It is important to review and take inventory of the content currently in the repository to get a clear picture on the structure, quality, and volume of the current data, so that potential issues can be addressed before the migration. The result of this analysis can further refine the scope, technical requirements, and timeline of the project.
Objectives
- Identify any potential issues with the current data
- Identify a subset of data which can be used for initial iterative testing
- Determine the level of effort and resources needed for migration
Suggested Collaborators
- Technical Lead
- Developers
- Functional Specialists, i.e. metadata librarians, digital preservation teams etc.
Example
Instructions
There are different ways to conduct a review of your current data. Typically, each institution has their own process for handling, reviewing, and updating their own data within their repositories. One example could be using spreadsheets to maintain metadata and data for all items contained within the repository in question, but information can quickly become out of date without regularly scheduled reviews. This risk may be a factor when you consider your individual use case.
One way to review your data is using Resource Index queries to return a list of content models and the number of objects associated with each model.
Follow these steps to determine content models and object counts in a Fedora 3.x repository:
Access the Resource Index (RI) at
/fedora/risearchRun the following ITQL query:
select $a from <#ri> where $object <fedora-model:hasModel> $a
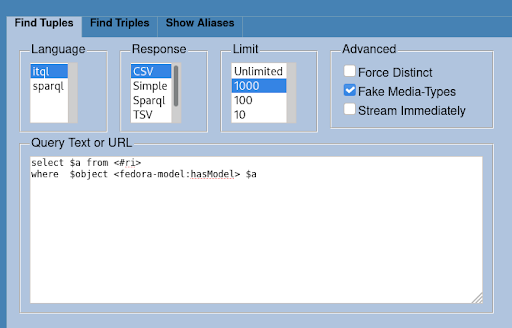
This will return a list of all content models in the repository.- Run the following query to determine how many objects of each type are in the repository.
select $object from <#ri> where $object <info:fedora/fedora-system:def/model#hasModel> <info:fedora/fedora-system:ContentModel-3.0>
- Use the content Model PIDs to locate each content model in the repository to examine its datastreams. Content models typically have a DS-COMPOSITE-MODEL datastream, which is an XML file that describes the required components of objects that use that model.
- If necessary, query the repository for objects that use each model and examine their list of datastreams, which should include not only the identifiers but also short descriptions of each datastream.
- Use this information to reconstruct the purpose and function of each content type in the repository and assemble a list. For an example from the UVA pilot, see UVA Fedora 3.x Objects.
Result Analysis
- Does this analysis expose any potential data migration issues? If so, what are the plans to mitigate these issues?
- How does the current state of the repository affect migration strategy and/or drive the selection of migration tools?
- How does the result of this analysis impact the project plan, including scope, timeline, technical requirements, resources needed, etc.?
Next Steps
- Based on the result of this analysis, document potential issues and mitigation plans, and update relevant details in the Project Plan.
- Resolve data issues before migration.
- Identify any data that should not be migrated (may be in outdated formats and/or already available in another format and accessed differently - e.g. derivatives served through IIIF)
- Identify a subset of the data to be migrated which can be used in an initial iterative migration test phase. That initial phase will be used to fine tune and confirm the infrastructure, migration processes, and successful migration of a small amount of the data. This test of the migration will reduce risk of delays inherent in migrating the entire data on each initial test.