Date
Call-in Information
Time: 12:00 pm, Eastern Time (New York, GMT-05:00)
To join the online meeting:
- Go to: https://duraspace.zoom.us/j/823948749
- Or iPhone one-tap :
- US: +14086380968,,823948749# or +16468769923,,823948749#
- Or Telephone:
- Dial(for higher quality, dial a number based on your current location):
- US: +1 408 638 0968 or +1 646 876 9923 or +1 669 900 6833
- Meeting ID: 823 948 749
- International numbers available: https://duraspace.zoom.us/zoomconference?m=Qy8de-kt6W4fMMDQCAV_3qfH1W-lxAo5
Attendees
![]() Indicating note-taker
Indicating note-taker
- Justin Littman
- Ralph O'Flinn
- Alex Viggio
- Benjamin Gross
- Brian Lowe
- Huda Khan
- Jim Blake
- Richard Outten
- Andrew Woods
Agenda
Logistics
- Defining the outputs of the fly-in
- Top-level architectural diagrams
- Component diagrams
- Inputs/Outputs for each component
- Draft HTTP API
- What are the salient features that will drive the architecture?
- What are the current bottlenecks, pain-points?
- Working documents
- Architectural diagrams
- Top-level and Detailed, component-level
- APIs and services, specified
- Features spreadsheet
- Questions to answer:
- What will the product will do/support?
- What additional business value-add can the re-architecture offer?
- What are core? and why?
- Which features are in/out/optional?
- What audiences are specific features for?
- What are the logical groupings for features into modules?
- Will we offer multiple product distributions, analogous to VIVO/Vitro?
- Perhaps an "enterprise VIVO" vs. a "small-shop VIVO" vs. Vitro
- Questions to answer:
- Architectural diagrams
- Meeting schedule leading up to Jan 29th
- Jan 10th @noon ET
- Jan 22nd @noon ET
- Jan 24th @noon ET
Notes
Audio recording
Questions / Observations for Straw-chitectures
vivo_arch_v1.png
- VIVO is separate from read-only sites
- Triplestore is central to VIVO
- Difference between Source Systems and staging/loaders?
- External Solr gets loaded by a loader?
vivo_arch_v3.png
- Scalable ingest
- No focus on refactoring VIVO
- How are loaders triggered?
- How are updates managed, from the UI?
- jb - Why keep "VIVO Triple Application" with its triple-store and inferencing? To provide a SPARQL endpoint? To provide an editing environment?
VIVO Product Evolution Straw
- Similar to above
- No focus on refactoring VIVO
- jb – At first glance, it appears to be straightforward to implement GraphQL as a layer over SPARQL. This might indeed insulate developers from SPARQL complexity, but it is unlikely to improve performance.
Screen Shot 2018-12-20
- Focus on VIVO refactoring
- How is performance and scale addressed?
- Is the frontend decoupled from the APIs?
- Server-side or client-side frontends?
- jb – Would the internal front-ends access the JSON APIs, or the existing controllers?
- jb – For the internal front-ends, Would there be any attempt to separate display from editing? Currently they are very much intertwined.
Future VIVO Example
- Focus on VIVO refactoring
- Maybe config does not need to be in a triplestore
- jb – Is the "New REST API" read/write or read-only?
- jb – Are the Legacy Freemarker pages just for admin functions, or are they also for searching, profile display, and profile editing?
- jb – Why the second search index? Is it more efficient, more flexible to populate two indexes?
VIVO 2.0 Arch
- Focus on VIVO refactoring
- Similar to above
- jb – This appears to be a draft of "Future VIVO Example"
arhitectura-vivo
- Addresses updates from UI and other sources
- Can service layer become the core VIVO app w/ content sources externalized?
- jb – What about policy filtering? (i.e., data is restricted from display and/or editing based on user accounts.) Currently, language filtering is applied at the SPARQL query level, but policy filtering is implemented higher in the stack. Where would policy filtering be implemented in this architecture? Or would it be dispensed with?
VIVO arch brainstorming
- jb – What is the benefit of JSON-LD? Isn't it just another RDF notation?
- jb – This might avoid one of the pitfalls of a graph model: the graph is one continuous structure, with no boundaries (ref: the deletion problem).
VIVO arch brainstorming-2
- No focus on refactoring VIVO
- Similar to Duke?
- Loader model
- What is the interation between webapps and content stores? API?
- What does deployment look like?
- Where does the VIVO ontology come into the picture?
- jb – What is the virtue of having both a triple-store and an RDBMS? What are the costs?
VIVO_Architecture_ideas.png
- jb – In the short run, the Data Distribution API is a good way to rapidly develop a back-end for an Angular/React/etc front-end.
ACTIONS
Collection of existing architecture diagrams / resources
- Diagrams
- Cornell (Huda)
- VIVO (in general)
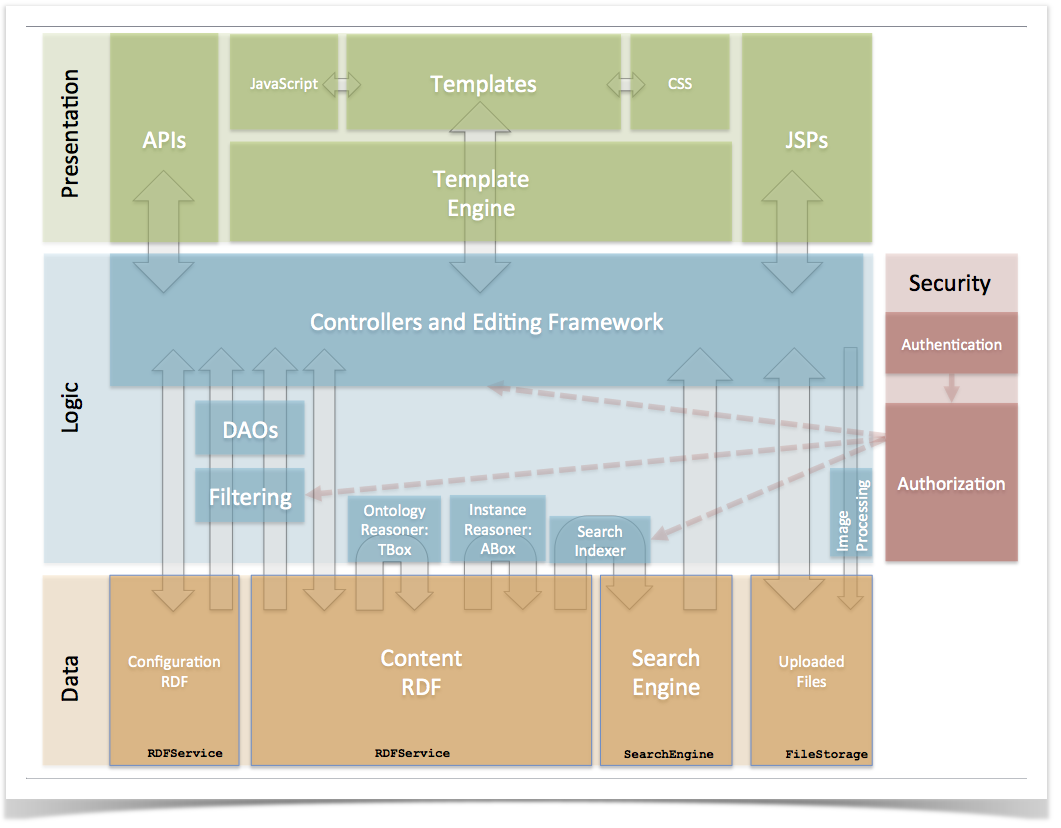
- From the wiki: diagram from architecture overview page
- component diagram from main architecture page
- Can include more brainstorming/high level component diagrams/discussions from presentations and documents as well but not sure this is the bullet for it
- From the wiki: diagram from architecture overview page
- Scholars at Cornell
- Presentation: https://figshare.com/articles/Scholars_Cornell_Visualizing_the_Scholarship_Data/5277958/1 (Slide 19 shows a high level overview of the components)
- Data Distribution API structure:
- image which shows API-related components (these would connect to VIVO)
- VIVO (in general)
- Cornell (Huda)
{kind=link}
{kind=link}
{kind=link}
Discussion
Previous Actions
- All to complete priority row
- All to review produce diagrams
Collect diagrams Opera (Brian)
Collect diagrams Rialto (Justin)
ACTION: ALL to help enumerate list of current features "Feature audit" (Google-doc)
- What to carry forward
- What to leave out
- Andrew to Potentially poll the community