Overview
The Book Solution Pack module allows for the creation of a book collection, and the ingesting of pages into that book. Essentially, a 'book' object is a special type of collection into which page objects can be ingested and organized.
A Book's PDF can be generated from each page. Pages are based on an uploaded pdf of the entire book or individual jpegs, or tiffs of every page. From the uploaded pages it is possible to generate images for use in the "Islandora Internet Archive Bookreader" or pdfjs viewer. It is also possible to generate PDF files per page. OCR and OCR coordinate data can also be generated from the uploaded pages.
Dependencies
Downloads
Release Notes and Downloads
Usage
The Book Solution Pack module functions slightly different than most other solution packs, in that it is a collection that acts similarly to a regular data object. Books exists as a collection, but are able to perform tasks like derivative creation and viewing similar to how other content models function.
There are a few steps to creating a book using the Book Solution Pack module:
- Create a new collection, or go to an existing one, and add the 'islandora:bookCModel' content model to its collection policy
- Go to that collection's 'Manage' tab, and add an object to the collection (from the 'Collection' section)
- Fill out the Book MODS form and submit it
You will now be brought to the Book's object page. From here, you can use the Paged Content module to manipulate the book. Check the Usage section of Islandora Paged Content for more information on how to add and manipulate pages within a book.
Configuration
The Book Solution Pack configuration page can be found at http://path.to.your.site/admin/islandora/solution_pack_config/book, and includes the following configuration options:
Create Page Derivatives Locally
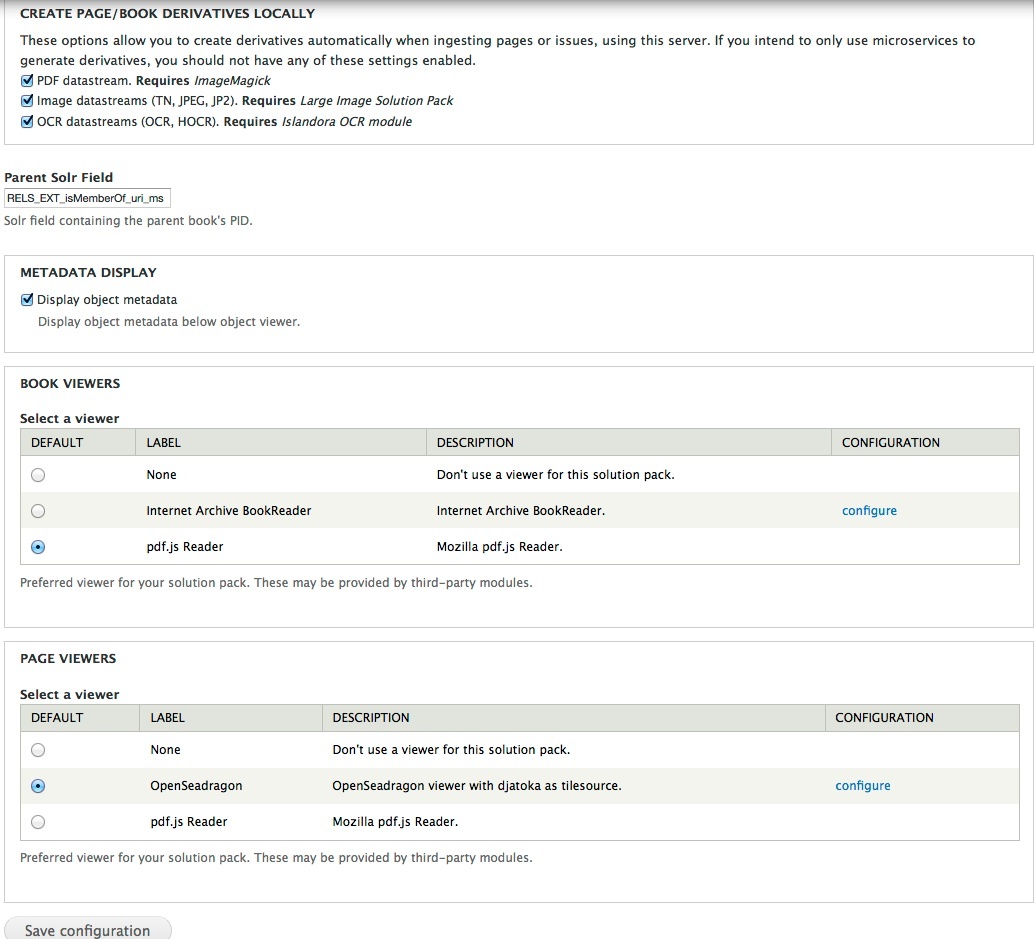
This section allows you to configure the Book Solution Pack module to create derivative datastreams for pages. The following derivative datastreams can be set, with their accompanying dependencies:
| PDF | ImageMagick |
| TN, JPEG, JP2 | Large Image Solution Pack |
| OCR, HOCR | Islandora OCR |
Solr Settings
These two fields define how Solr is able to find the PID of a page's parent book, and that page's number, respectively. Changing these fields requires a working knowledge of Solr queries and RDF, and for the most part, they should remain untouched.
Book Viewers and Page Viewers
These two sections change how Islandora handles a request in the the 'View' tab of a Book object and Page object, respectively. Islandora includes out-of-the-box support for the Internet Archive Bookreader and OpenSeadragon as book and page viewers; check the links in the Dependencies section above for more information on installing these components.
Content Models, Prescribed Datastreams and Forms
The Book Solution Pack comes with the following objects in http://path.to.your.site/admin/islandora/solution_packs:
- Islandora Internet Archive Book Content Model (islandora:bookCModel)
- Book Collection (islandora:bookCollection)
A book ingested with all derivative creation options checked will have the following datastreams:
| RELS-EXT | Default Fedora relationship metadata |
| MODS | MODS metadata form |
DC | Dublin Core record |
| TN | Thumbnail image |
PDF | PDF derivative created by ImageMagick |
Check Islandora Paged Content for information on an individual page's datastreams.
The Book Solution Pack comes with the Islandora Book MODS form.
Batch Processing
An optional module to process multiple book + page objects is available.
