Architecture Diagram
The following diagram shows the primary components that make up Fedora 4, and how they interact with each other and with external clients such as the Java client currently being developed, or a Hydra application.
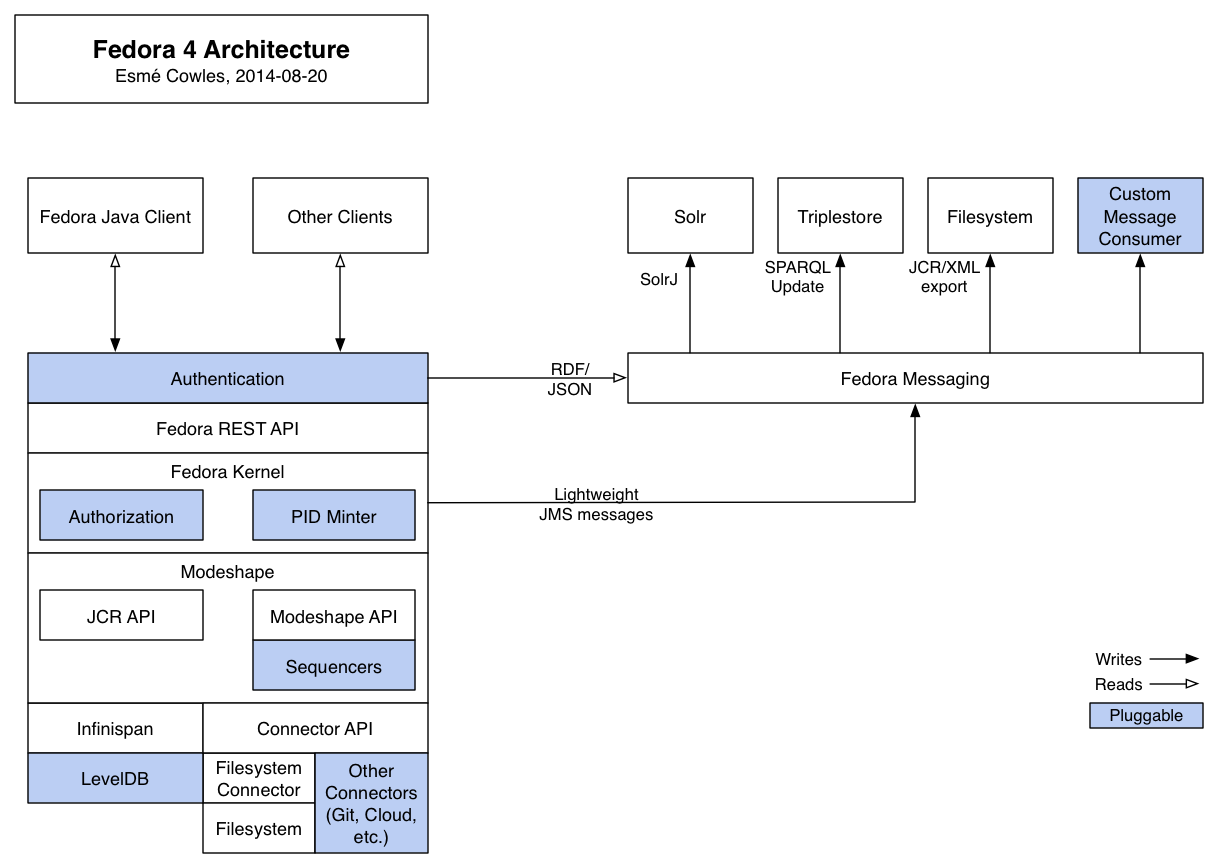
Pluggable Components
- Authentication: authenticating requests is typically handled by the servlet container running the Fedora 4 webapp, and can usually be configured to support a wide range of authentication types.
- Authorization: there are currently modules for role-based authorization and XACML authorization, and custom authorization modules can be created to support other authorization types.
- PID Minter: there are currently PID minter modules that generate random UUID identifiers, or retrieve PIDs from an external web service, and custom PID minter modules can be created for other PID minting scenarios.
- Sequencers: the Modeshape API allows creating sequencers which are tightly-coupled asynchronous modules which can be configured to automatically process new and updated content.
- LevelDB: the default configuration uses LevelDB storage, but Infinispan supports several other storage mechanisms.
- Other Connectors (Git, Cloud, etc.): Modeshape supports a few other storage options with connector implementations, which could be extended to support Fedora 4. Custom connectors could also be developed to support other storage systems.
- Custom Message Consumer: the messaging system currently has modules for Solr and Elasticsearch indexing, triplestore synchronization using SPARQL Update, and serializing JRC/XML to disk. Custom modules can be created to support syncing with other systems, or performing a broader array of tasks such as format migration or fixity monitoring.
13 Comments
A. Soroka
Andrew Woods
Raw files are available as attachments to this page:
A. Soroka
Thanks, Andrew Woods!
Unknown User (escowles@ucsd.edu)
A. Soroka: good points all around. For this diagram, would it be enough to just have another block on top of the REST API called "Access Control (optional)"? Then somebody who knows how the access control works can create a second diagram of it?
A. Soroka
Sure-- that's a good way to "set a bit" for it. Maybe Greg Jansen is the person to put details into it?
A. Soroka
It would be good to start noting where components are reasonably "pluggable" now (e.g. LevelDB) and where they are not (e.g. ModeShape). Perhaps with some simple coloring?
A. Soroka
For public consumption, I think we need to diagram the architecture sans Hydra. It would be good to have "Fedora-with-Hydra" diagrams available, for exposition, but showing Hydra alongside the basic architecture is going to confuse people.
Andrew Woods
The "Access Control" box should likely be split into two:
A. Soroka
Perhaps we should break out a "Connectors" box (pluggable) to include "Filesystem Connector"? There are other connectors and could be more of them, and that might be of interest to folks.
A. Soroka
Should we notate the REST API as being an HTTP API that subsumes LDP?
Chris Beer
From TWG 8/20:
Indexer API: is it a generic mechanism, or tied specifically to indexing? It could be made generic, but depends on additional implementations.
Rename indexer box to e.g. “message consumer” to indicate the concept has broader applicability?
A. Soroka
If we renamed the Indexer, we should rename packages and classes in the code to remove the many mentions of "indexing".
Chris Beer
Distinguish between core vs pluggable components to show the decoupled model.