Introduction
The DSpace API was originally created in 2002, very little has changed in the way we work with our API. After working with the API day in day out for over 7 years I felt it was time for a change. In this proposal I will highlight the issues that the current API has and suggest solutions for these issues.
How things are now
Bad distribution of responsibilities
Currently every database object (more or less) corresponds to a single java class. This single java class contains the following logical code blocks:
- CRUD methods (Create & Retrieve methods are static)
- All business logic methods
- Database logic (queries, updating, …)
- All getters & setters of the object
- ….
Working with these types of GOD classes, we get the following disadvantages:
- By grouping all of these different functionality's into a single class it is sometimes hard (impossible ?) to see which methods are setters/getters/business logic since everything is thrown onto a big pile.
- Makes it very hard to make/track local changes since you need to overwrite the entire class to make a small change.
- Refactoring/altering GOD classes becomes hard since it is unclear where the database logic begins & where the business logic is located.
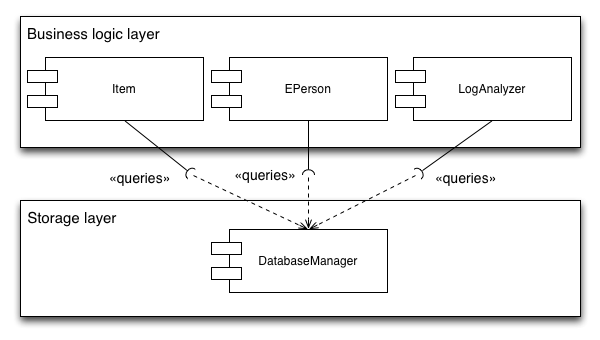
Database layer access
- EPerson table is queried from the Groomer and EPerson class.
- Item is queried from the LogAnalyser, Item, EPerson classes
This makes it hard to make changes to a database table since it is unclear from which classes the queries are coming from. Below is a schematic overview of the usage of the item class:
Postgres/oracle support
String params = "%"+query.toLowerCase()+"%";
StringBuffer queryBuf = new StringBuffer();
queryBuf.append("select e.* from eperson e " +
" LEFT JOIN metadatavalue fn on (resource_id=e.eperson_id AND fn.resource_type_id=? and fn.metadata_field_id=?) " +
" LEFT JOIN metadatavalue ln on (ln.resource_id=e.eperson_id AND ln.resource_type_id=? and ln.metadata_field_id=?) " +
" WHERE e.eperson_id = ? OR " +
"LOWER(fn.text_value) LIKE LOWER(?) OR LOWER(ln.text_value) LIKE LOWER(?) OR LOWER(email) LIKE LOWER(?) ORDER BY ");
if(DatabaseManager.isOracle()) {
queryBuf.append(" dbms_lob.substr(ln.text_value), dbms_lob.substr(fn.text_value) ASC");
}else{
queryBuf.append(" ln.text_value, fn.text_value ASC");
}
// Add offset and limit restrictions - Oracle requires special code
if (DatabaseManager.isOracle())
{
// First prepare the query to generate row numbers
if (limit > 0 || offset > 0)
{
queryBuf.insert(0, "SELECT /*+ FIRST_ROWS(n) */ rec.*, ROWNUM rnum FROM (");
queryBuf.append(") ");
}
// Restrict the number of rows returned based on the limit
if (limit > 0)
{
queryBuf.append("rec WHERE rownum<=? ");
// If we also have an offset, then convert the limit into the maximum row number
if (offset > 0)
{
limit += offset;
}
}
// Return only the records after the specified offset (row number)
if (offset > 0)
{
queryBuf.insert(0, "SELECT * FROM (");
queryBuf.append(") WHERE rnum>?");
}
}
else
{
if (limit > 0)
{
queryBuf.append(" LIMIT ? ");
}
if (offset > 0)
{
queryBuf.append(" OFFSET ? ");
}
}
Alternate implementation of static flows
// Should we send a workflow alert email or not?
if (ConfigurationManager.getProperty("workflow", "workflow.framework").equals("xmlworkflow")) {
if (useWorkflowSendEmail) {
XmlWorkflowManager.start(c, wi);
} else {
XmlWorkflowManager.startWithoutNotify(c, wi);
}
} else {
if (useWorkflowSendEmail) {
WorkflowManager.start(c, wi);
}
else
{
WorkflowManager.startWithoutNotify(c, wi);
}
}
if(ConfigurationManager.getProperty("workflow","workflow.framework").equals("xmlworkflow")){
// Remove any xml_WorkflowItems
XmlWorkflowItem[] xmlWfarray = XmlWorkflowItem
.findByCollection(ourContext, this);
for (XmlWorkflowItem aXmlWfarray : xmlWfarray) {
// remove the workflowitem first, then the item
Item myItem = aXmlWfarray.getItem();
aXmlWfarray.deleteWrapper();
myItem.delete();
}
}else{
// Remove any WorkflowItems
WorkflowItem[] wfarray = WorkflowItem
.findByCollection(ourContext, this);
for (WorkflowItem aWfarray : wfarray) {
// remove the workflowitem first, then the item
Item myItem = aWfarray.getItem();
aWfarray.deleteWrapper();
myItem.delete();
}
}
Local modifications
Take for example the WorkflowManager, this class consist of only static methods, so if a developer for an institution wants to alter one method the entire class needs to be overridden in the additions module. When the Dspace needs to be upgraded to a new version it is very hard to locate the changes in a class that is sometimes thousands of lines long.
Inefficient caching mechanism
DSpace caches all DSpaceObjects that are retrieved within a single lifespan of a context object. The cache is only cleared when the context is closed (but this is coupled with a database commit/abort) or when explicitly clearing the cache or removing a single item from the cache. When writing large scripts one must always keep in mind the cache, because if the cache isn't cleared DSpace will keep running until an OutOfMemory exception occurs. So contributions by users with a small dataset could lead to hard to detect memory leaks until the feature is tested with a lot of data.
Excessive database querying when retrieving objects
When retrieving a bundle from the database it automatically loads in all bitstreams linked to this bundle, for these bitstreams it retrieves the bitstreamFormat. For example when retrieving all bundles for an item to get the bundle names all files and their respective bitstream formats are loaded into memory. This leads to a lot of obsolete database queries which aren't needed. Improvements have been made on this section but it still requires a lot of coding to "lazy load" these objects.