OCROverview
This module acts a Toolkit for generating OCR and word coordinate information. At the moment it relies exclusively on Tesseract to generate this information.
Tesseract
Tesseract is an OCR engine that was developed at HP Labs between 1985 and 1995. It is currently being developed at Google. Recognized as one of the most accurate open source OCR engines available, Tesseract will read binary, grey, or colour images and output text.
A TIFF reader that will read uncompressed TIFF images is also included. Islandora Book Solution Pack currently uses Tesseract version 3.2.2, which can be obtained from the project home page. Lower versions are not supported.
Dependencies
Tesseract installation will differ depending on your operating system; please see the Tesseract README Wiki for detailed instructions.
Downloads
Release Notes and Downloads
Installation
Install as usual, see this for further information.
Configuration
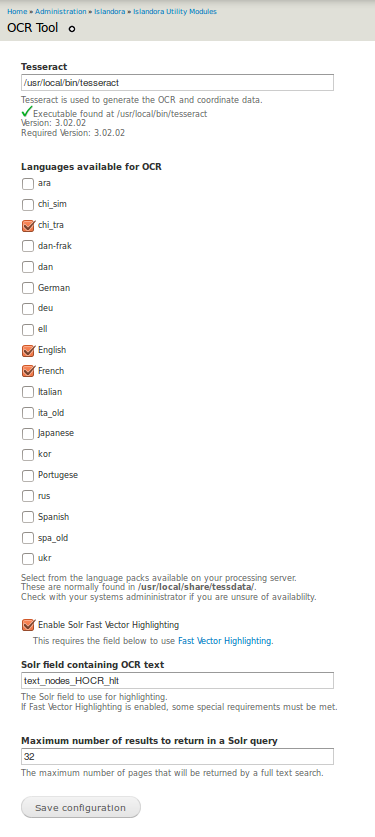
In Administration » Islandora » Islandora Utility Modules » OCR Tool (admin/islandora/tools/ocr), configure the following:
- Set the path for Tesseract
- Select languages available for OCR
- Enable/disable Solr Fast Vector Highlighting
- Set Solr field containing OCR text and the maximum number of results to return in a Solr query
To have Islandora viewers recognize Solr search results and highlight them, one will need to configure Solr to index the HOCR in a particular fashion.
The field that the HOCR is stored in must have the following attributes: indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true"
Each text node of each element in the HOCR datastream must be placed in order in a single value for the Solr field with all whitespace sub strings normalized to a single space.
Any objects that were previously ingested but require this functionality will need to be re-indexed.
Reference Implementation
Tesseract provides many languages which can be downloaded from here.
To install just unzip them in your tessdata directory, typically located at /usr/local/share/tessdata
If you want to add your own languages or train your Tesseract for your specific needs please review the documentation here
It is recommended to check the Tesseract page for more information on these options.
