...
- Ingest must support varied and currently unknown data sources
- Ingest must be scalable: the use of different backend triplestores or datastores must be allowed to support site-specific scaling requirements
- Ingest must support both JSON and RDF (note: JSON content must have a known mapping to RDF model)
- Content must be validated before being ingested. Example validation mechanisms: SHACL, ShEx, JSON Schema
- Ingest must expect models/shapes that are expected and able to be validated (note: initial models can be derived from what is in use in Freemarker UI)
- Ingest tooling must support two modes of operation: hands-free (automated) and curated
- Ingest tooling must support curation of data prior to ingest: disambiguation and reconciliation of entities
- Ingest will be entity-centric vs triple-centric. Example entities: Person, Grant, Publication, Authorship
- Ingest tooling must not require the use of a specific programming language
- Ingest must support realtime, incremental updates
Out of scope
- Extraction of data from data sources
- Transformation of data from data sources
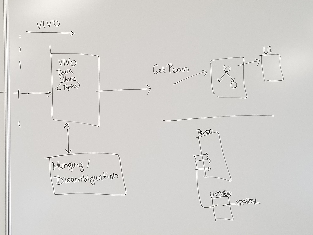
Below: DS1-3: Data sources, read in and validated based on “shapes” (or patterns or sets of triples representing entities), with entity resolution/URI creation as required, leading to a set of triples that can be read into VIVO. The arrow on the right side of the picture continues to VIVO in the next picture.

Below: The previous picture represents a view of the combine/ingest process that leads to VIVO in this picture (the munging/disambiguation box was supposed to be moved to the ingest process instead). Triples can then be requested for different entities which provide a UI. The portion on the bottom right identifies how the current VIVO system uses SPARQL queries defined in list views which together define what is expected to be displayed for specific entity types.
UI
Requirements
- Current Freemarker UI will stay in-place for the scope of this plan (although deprecated)
- UI must provide read access to VIVO data
- UI must minimally be informed by the Production Evolution effort
- UI must be based on data coming from a JSON endpoint
- UI should render data served by a GraphQL server
- GraphQL server should be configured with the same models used by ingest tooling (note: DocumentModifier.java may be updated to populate search index with these models)
- UI must support accessibility
- UI must support internationalization (i18n)
- UI should avoid querying the triplestore when rendering
Decoupling VIVO
Requirements
Architectural concerns
- From an architectural perspective, having a triplestore at the core of the application brings significant limitations
- As we decouple components, we must ensure that we also decouple logic expectations between the components
...and more