Modeshape 4.4.0 includes several new mixins that change the behavior for storing children of Nodes. Adding these mixins triggers storing child nodes in a progressively larger number of buckets, which is intended to improve performance with large numbers of children. See Modeshape's Unordered Large Collection documentation for more information.
Containers Tested
| Name | Container | Child Nodes |
|---|---|---|
| PairTree | default | default auto-generated IDs |
| Flat | default | all children created directly in the container |
| Tiny | mode:unorderedTinyCollection | all children created directly in the container |
| Small | mode:unorderedSmallCollection | all children created directly in the container |
| Large | mode:unorderedLargeCollection | all children created directly in the container |
| Huge | mode:unorderedHugeCollection | all children created directly in the container |
Tests
Creating Containers
For each type tested (Flat, Tiny, Small, Large, Huge), use Curl to create 100 children. Count the number of seconds to create the 100 children (write time).
- Status: Errors after 20K children created in each container
- Write Performance: Tiny and Small performed best, scaling smoothly through 20K children; Flat and Large slowed more; and Huge slowed dramatically.
Chart showing seconds to create 100 children:

Creating and Reading Containers
For each type tested (PairTree, Flat, Tiny and Small), use Curl to create 100 children, list children in the container, and retrieve 100 children. Count the number of seconds to create the 100 children (write time), and the number of seconds to list and retrieve the children (read time).
- Status: 50K children created in each container
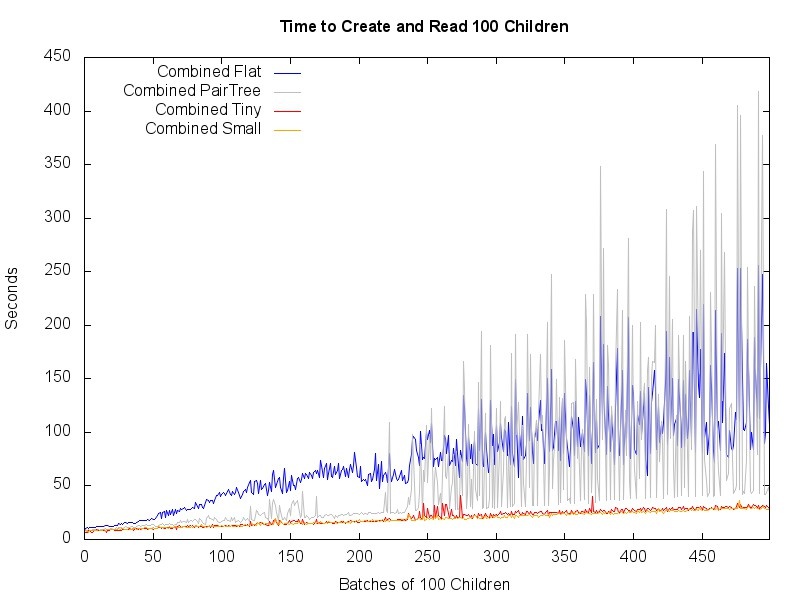
- Read Performance: Tiny and Small are scaling smoothly; Flat and PairTree are slower and increasingly variable after 25K children.
- Write Performance: PairTree, Tiny, and Small are scaling smoothly; Flat is slowing down much more dramatically and increasingly variable starting around 12K children.
Chart showing seconds to create and read 100 children:
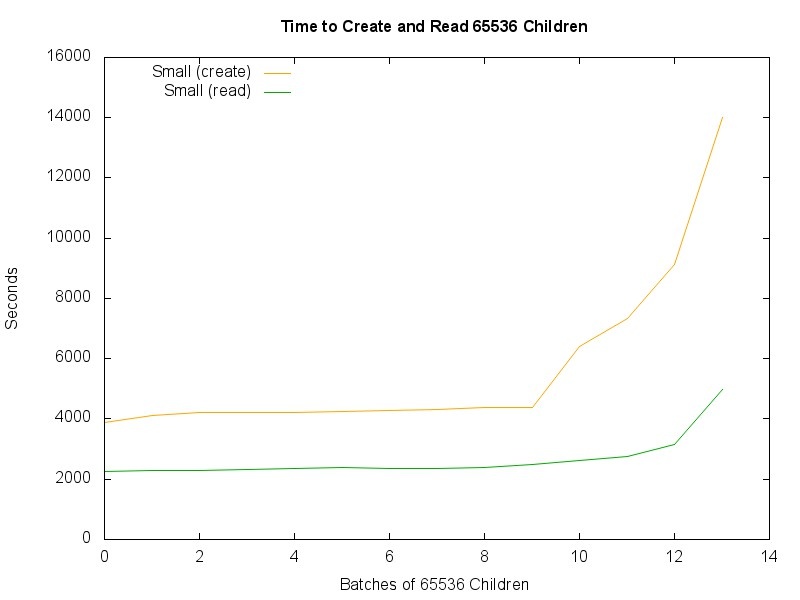
Creating and Reading Containers (Part 2)
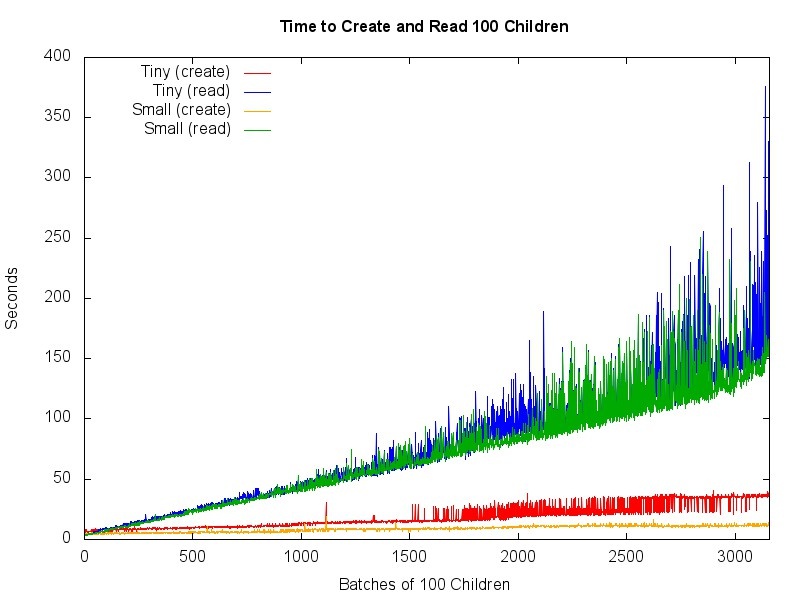
Based on the previous test, the Tiny and Small unordered collections seemed the most promising. Repeat the previous test with only Tiny and Small containers, and continue testing with larger numbers of children to see how many children they can contain before performance degrades.
- Status: 300K children created in each container
- Read Performance: Both scaling smoothly through 100K children, and becoming more erratic afterwards, with Small performing marginally better.
- Write Performance: Both scaling smoothly, with Small performing significantly better.
Creating and Reading Containers (1-Level Hierarchy)
To see if the limitation was the number of children directly under a single container, run a new set of tests with a 1-level hierarchy, with 1000 contianers each containing 1000 children.
- Status: 300K children created in each container
- Read Performance: Very little difference between the different container types, with performance degrading sharply after about 275K children.
- Write Performance: Very little difference between the different container types, with performance degrading sharply after about 225K children.

Creating and Reading Containers (2-Level Hierarchy)
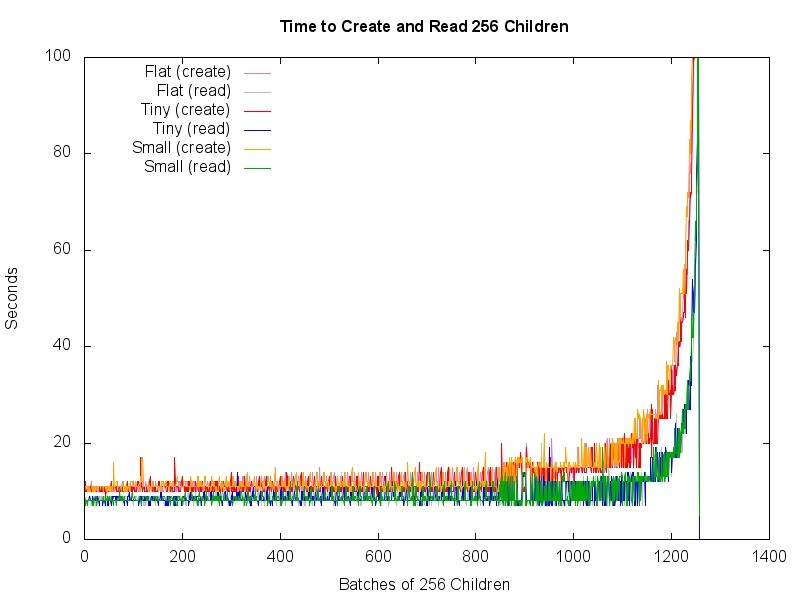
To see if a deeper hierarchy would improve performance, run a new set of tests with a 2-level hierarchy, with 256 containers, each containing 256 child containers, each containing 256 children.
- Status: 300K children created in each container
- Read Performance: Very little difference between the different container types, with performance degrading sharply after about 1150 batches (295K children).
- Write Performance: Very little difference between the different container types, with performance degrading sharply after about 1150 batches (295K children).
Creating and Reading Containers (3-Level Hierarchy, 100 Nodes per Level)
To see if using multiple container types in the same tests and repository was impacting other container types, run a new set of tests with only Small containers, with a 2-level hierarchy, with 100 top-level containers, each containing 100 child containers, each containing 100 children.
- Status: 600K children created
- Read Performance: Steadily increased until around 600K children, then repository failure.
- Write Performance: Roughly constant with increasing repository size.

Creating and Reading Containers (2-Level Hierarchy, 2K Nodes per Level)
Trying a flatter hierarchy, with a larger number of child nodes at each level: 2048 top-level containers, each with 2048 children.
- Status: 1.2M children created
- Read Performance: Very slowly increasing until around 1.2M children, then dramatically increasing.
- Write Performance: Very slowly increasing until around 1.2M children, then dramatically increasing.

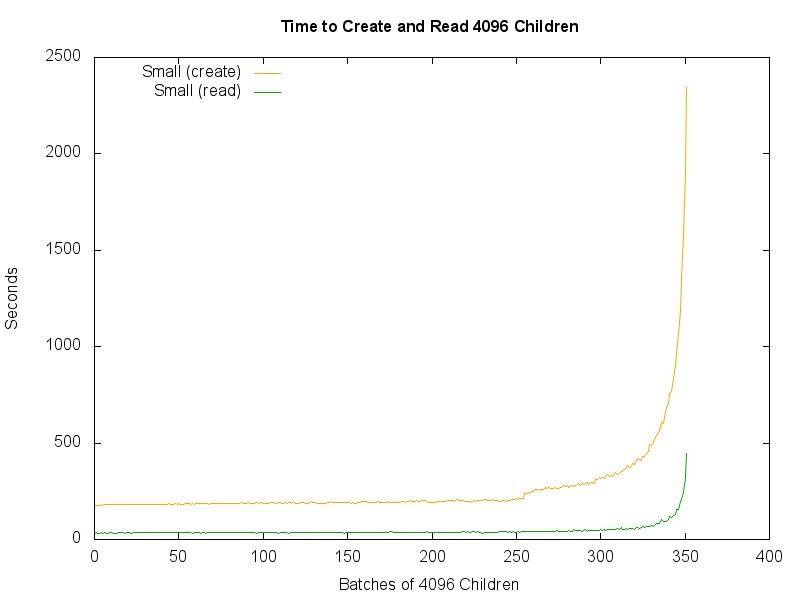
Creating and Reading Containers (2-Level Hierarchy, 4K Nodes per Level)
Trying a larger number of child nodes at each level, 4096 top-level containers, each with 4096 children.
- Status: 1.4M children created
- Read Performance: Very slowly increasing until around 1.4M children, then dramatically increasing.
- Write Performance: Very slowly increasing until around 1.4M children, then dramatically increasing.
Creating and Reading Containers (2-Level Hierarchy, 64K Nodes per Level)
Trying a larger number of child nodes at each level, 65,536 top-level containers, each with 65,536 children.
- Status: 850K children created
- Read Performance: Very slowly increasing until around 590K children, then sharply increasing.
- Write Performance: Very slowly increasing until around 785K children, then sharply increasing.
14 Comments
Andrew Woods
Can you detail what each of these means? As well as attach your example repository configurations?
Andrew Woods
Are you saying that each of the tests errored-out after 20k children?
Esmé Cowles
The test was testing each of them in turn. So when the Huge test ran into errors and Tomcat ran out of memory, I stopped the whole test and began the second test on the more promising types.
Andrew Woods
What are the units of the x and y axes?
Esmé Cowles
I've updated the graph to include axes and rename "Normal" to "Flat" to match the wiki text.
Andrew Woods
Since "flat" is not in the graph, is it safe to assume that it was not tested?
Andrew Woods
It would also be interesting to know how long the various container types continue to scale consistently, beyond 20k or 45k children.
Esmé Cowles
My plan was to let the second test run until 50K children, and then start a third test to compare the Tiny and Small types and let that go as large as possible.
Ben Pennell
Are the hardware specifications used for these tests documented somewhere?
Did you run out of memory after 20k updates with every test, or only during the first set of tests?
Based on the last two findings, does that indicate that a repository would not scale past 300000 children per container, even with child nesting, if the base container were configured as a tiny, small (or flat)? I suspect I'm misunderstanding since previous tests don't show more linear growth with similar amounts of nested hierarchy (Large Numbers of Containers)
I'm a bit concerned that there are no instances in which anything outperforms tiny and small, even at scale, as I assume the modeshape group had reasons for creating the other larger types. Perhaps large collections start to perform relatively better in the tens of millions range? But if you can never get there...
Esmé Cowles
Ben-
The hardware used for the tests are two VMWare VMs configured with 4x 2.8GHz Xeon CPUs and 16GB RAM (Tomcat's JVM has 8GB of that). I only ran into OutOfMemoryError on the first set of tests, after that I updated my scripts to restart Tomcat after each batch. I believe that better tuning of the memory options should make that unnecessary, but it was the easiest way to move forward.
I have continued testing with a few other scenarios but haven't updated the wiki yet. I started testing only Small to avoid problems with other container types or other nodes from impacting the tests. Using only Small, I've been able to create much more than 300K containers (1,400,00 or so I think). I agree I was expecting other types to perform better in some circumstances, but that not what I've seen. If you have hardware to test on, I would be interested to see if you get the same results.
Ben Pennell
I should have some hardware for rerunning the tests soon, although not exactly the same of course. Do you have a testing suite that I could reuse? I'm also very interested in the rest of your findings. We are trying to model our repository data in fcrepo4, and part of that is determining whether to go with a flat or nested hierarchy.
Esmé Cowles
Ben-
I've put my scripts up on github: https://github.com/escowles/fcrepo-scale-testing – the scripts assume that you're using a modified CND file with the Modeshape unordered collections defined (see https://github.com/fcrepo4/fcrepo4/compare/unordered-collections).
I think the best performance I've seen is with a 2-level hierarchy and 4096 nodes per level:
CreatingandReadingContainers(2-LevelHierarchy,4KNodesperLevel)
Andrew Woods
That is interesting, Esmé Cowles. The 4k child performance threshold you are seeing is similar to what we have seen in the past with "normal" Modeshape node types. Is the "mode:unorderedSmallCollection" nodetype helping us?
Esmé Cowles
I'm re-running the 4k children test again without adding the unorderedSmallCollection. At least for the first few batches, it's taking more than twice as long to create the children (~500 sec instead of ~180 sec)