Table of Contents
DuraCloud for Research Architecture
Background
A series of meetings have been held with the DfR Architecture/Development team and a workshop attended by key community members, conducted by Jonathan Markow to identify features in the form of user stories. Subsequently we have prioritized those stories to identify those capabilities that are critical to this work but informed by a strategic view that frames it. From this information, we are developing this proposed architecture for the DfR-related services.
As a very short summary of the work-to-date, the following critical capabilities have been identified:
- The "missing piece" is a service to capture research materials from the operational environment used to create those materials.
- This service must require minimal effort from the researcher (or delegates) but provide immediate and visible benefit to them.
- Should provide a path for capturing the context and provenance information to support reproducible science during and after the life of the projects that created the materials but this must not impact the researcher and is not a source of motivation for them now.
- There must be adequate policy enforcement from the initial operational deployment to support deposit and access controls to ensure trust in the service
- Not all the features identified will be supported at the beginning; therefore, an open, evolvable and extensible approach must be used that leverages DuraSpace and community resources to support researcher needs.
An important resource is the "first cut" architecture documented by Bill Branan, subsequent to the DTR workshop. It has turned out to be a remarkably accurate starting point and included a basic architecture drawing from which this work is derived:
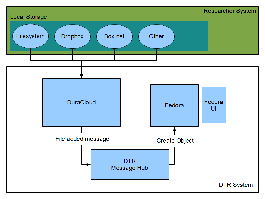 .
.
As a result of these meeting the project was renamed to DuraCloud for Research since it is much closer to the concepts resulting from these meetings.
–
On December 22nd, Chris and Andrew discussed design in a bit more detail and came up with the following strawman diagram, for discussion at the Philadelphia meeting in January.
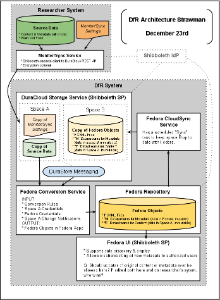
(Editable source is this Google Doc)
–
In March 2012, Bill drew a simplified architecture diagram for presentation at the LibDevConX^3 conference:

(Editable source, in powerpoint format, is available here: slide 16)
Summary Concept of Operations (CONOPS)
A Concept of Operations describes how the service will work from a users point of view. While a full CONOPS has a formalized set of standards, a simplified form, adapted for agile development, was used for this document.
Summary Glossary
This section provides definitions for selected terms and users (also called actors) used in the stories and in other parts of the architecture. During this work a more complete glossary will be developed. This does not mean that the definitions contained in the glossary are in any way definitive but just permit use to provide a consistent definition we can use for this project.
Research
Researcher
Research Materials
Data
Subset
Selection
Search
Analysis
Correlation
Service Administrator
Account
Access
Deposit
Copy
Research Materials
Research Information Life Cycle
Summary of Operations
The significant increase in the production and collection of scientific data is appropriately referred to as a “data deluge”. Researchers and scholars confronting this deluge and are faced with new data management challenges that have both social and technical dimensions. From the social perspective there are fundamental open questions pertaining to roles, responsibilities, and processes for responsible data stewardship and curation. From the technical perspective, there are currently many types of systems in use for data management including an array of non-standard systems, grid-‐based storage networks and, to a lesser degree, institutional repositories such as DSpace, Fedora, and enterprise solutions from various vendors. Even within a single institution, there are no standards for storing data, resulting in ad hoc approaches and variability across departments and individuals. Unfortunately, there are also idiosyncratic “data under the desk” approaches, where researchers and scientists go it alone by storing and managing valuable data in their personal computing environment with commodity computers and local storage devices.
Cloud-based storage and compute services have gathered considerable attention with the promise of reducing cost, increasing availability and removing impediments in provisioning resources just when needed. It is also, using a Cloud to have pre-configured services ready for use with minimal startup and operational administration. These characteristics complement supercomputer (high performance computing) resources, since, while a Cloud can provide enormous parallel compute resources, it is not optimized for same sort of processing that is done by HPC centers. Similarly, the a Cloud does not substitute for laboratory instrumentation or non-networked (field) computing. However, a Cloud can provide easy setup of ordinary computing resources and can provide a safe home for copies of research materials in digital form, augmenting the compute resources of the researcher.
A Cloud is an approach for managing a group of commodity computing resources using a common administrative infrastructure. Most large higher-education institutions are in the process of converting to private Clouds to make the best available use of their limited resources. There are also public for-profit Clouds notably Amazon's. Since these Clouds are networked, services and storage can be used between any of them noting that they are administered and billed separately. Generally, a Cloud is identified by its provider, the organization that owns and manages it.
DuraCloud is both software and "software as a service" (SAAS) that is independent of any single Cloud provider. In essence, it is a virtual Cloud working with any interested and compatible Cloud provider both private and public. It is a non-profit organization with participants from many educational, research and scientific institutions. DuraCloud for Research (DfR) is a new project, funded by the Sloan Foundation, to help researchers (and research institutions) take advantage of Cloud-related capabilities, and develop new capabilities that enhance the research process.
DfR has the opportunity to reduce the impact of the data deluge on researchers — enabling them to concentrate on their real work — by automating many of the rote activities for handling digital research material. But DfR also has the opportunity to do much more since "value added" services can easily operate on data when copies reside in a Cloud. It is the work of this project to analyze researcher and research institution needs — then build software and offer services to meet those needs.
Enterprise-class Cloud Backup
The first goal of DfR is to enable backup to a Cloud storage infrastructure that automatically makes copies of research materials to a remote location, but still under the control of the research and/or institution. Having remote copies serve in the role of "backup" for research materials, particularly when only one copy exists on a computer "under the desk". Having the only copies in the same location does not protect you from losing your work to damage or destruction of the computer's storage or secondary backup (disk or tape). The copy must be remote.
For the purpose of DfR we define the the place where copies of research materials are used every day as "operational storage". Research materials are not just the data but includes software, papers, notes, calibration records, email — really anything in digital form that the researcher uses. It can also include surrogates, like photos of physical samples.
But the CONOPs for DfR imagines something more than backup. Having backups is very good but limiting. The biggest problem with backups is that you can lose the organization of the materials. Usually, the only organization you can save is the directory structure, at it changes over time. DfR needs to capture and maintain the relationships between research material. Also with backups, you may not be able to capture metadata that helps you characterize the research materials.
One feature identified by this project that researcher's want help in "finding their stuff". This is particularly hard when the "stuff" is on a collaborators or assistants laptop.
Providing an automated copy in safe storage was the highest priority identified since it solves the backup requirement but also enables other capabilities that help researchers in their work. These capabilities are describe in other sections of the CONOPS.
Please refer to the picture below. We cannot describe all of the capabilities imagined in the DfR in one picture so the picture below describes a part of the automated backup capability. It is similar to other remote copy capabilities but it is conceived to be an open but trusted approach to creating a network of storage providers.

Research materials (notably data) usually originates in the researcher's "work space." The may be a laboratory, office, from an instrument or papers plucked from a library. There are so many potential "work spaces" we cannot enumerate them here. And research materials are shared between researcher's, research assistants and staff (often by thumb drive). Team members come and go, often taking the only copy of research materials with them. Commonly organization of the research material is in someone's head (at worst) or by a piece of software (sometimes hard to figure out).
Regardless, the body of work created by researcher (in digital form) is documented (authored) in the work space. Therefore, the researcher must have unfettered access to the storage resources serving the work space. We have termed this "operational storage" and is depicted in the lower right. Operational storage may be located in the researchers lab (on machines under direct control) or may be located in the institutions storage pool — or may be in Google Docs. Like "work spaces", there are just too many permutations of "operational storage" to enumerate here. Regardless, the common characteristic of operational storage is at the beginning of the "information (data) life cycle" and the front line of the research process.
To automate a "safe" Cloud storage infrastructure, the DfR requires that a "synchronization client" and optionally a "monitor" be added to watch the operational storage. In many cases, the monitor will "watch" disk storage for changes. But since operation storage may be part of an instrument, software, HPC center or workflow system like Taverna or Kepler, the monitor may be placed where data is moving from place-to-place. This is the most intrusive part of the DfR concept. We already find similar software from commercial sources like "Box.net". However, DfR software is open source and originated from the research community. Indeed, anyone can supply the software so long as it meets a well defined specification. DfR is working with Internet2 and other organizations to help develop this specification, a critical part of this project. Alternately, commercial or open monitored storage products may be used like DropBox, SAM/QFS (hierarchical) or grid-related products. Anything that can provide a notification that the storage has changes should be feasible to instrument.
You will find on the drawing a number of other elements. First, each "Cloud" indicates a "Cloud Provider". The cloud provider may be your institution. Other Cloud Providers may be other institutions that a storage collaborators. Those institutions may also house research collaborators. The advantage to the researcher of having additional cloud providers is that having many remote copies reduces the chance of losing your research materials. There can be other providers and consumers of your data (as indicated in the upper right hand corner) by connections to other operational storage (for example an HPC center).
For several reasons, each storage collaborator must implement a storage monitor. By implementing a storage monitor, a provide joined a "circle of trust". Really, its a network of trust because any authorized. collaborating storage providers can communicate to any other one (again the "network effect" provides a number of benefits to the research.
For this discussion, the "safe" storage network acts only to make copies of the research materials controlled by policies set by the researcher (and/or institution). This starts with choosing (setup) of a monitoring plan. The details of this plan are still in work but will include what materials to copy, what should trigger the copy and what providers get the copy. Support for versions of files and file organizations (like directories) are part of its concept. The researcher (or a person delegated by the research) would set up the "storage plan" from a service hosted by one of the storage providers. The storage plan would be sent to the researcher's operations storage monitor and all the collaborating storage providers. After all, all the collaborator needs to understand your plan.
Thereafter, the storage provider network synchronizes your operational storage with their copy storage. The synchronization can be one way (to the provider or to you), both ways, with or without versions, automatic or on-demand. So when a laptop walks out the door, you can fetch back it monitored contents (but not the personal ones outside the plan).
Additional Topics
- Web of Trust, Policy, Policy Enforcement
- Backup does not solve many requirements for the "data life cycle" (move that to a data life cycle section).
- Institutional Repositories don't work well for research data and and research workflow.
- Storage Infrastructure
Summary User Stories
This section contains selected high level user stories. These stories are not intended to cover the entire DfR service in detail; indeed too much detail may obscure the core functions.
DfR Service Architecture
Services, Components and Aspects
Security
Object Creation Service
Service Execution Environment
Service and Component Interactions
Service and Component Interfaces
Technologies
Cloud
DuraCloud
Eucalyptus
Commercial Cloud
Box.net/DropBox like
Replication Services
SAM/QFS
Bus/Orchestration Services
Messaging/Notification
iRODS
Grid Workflow (Taverna, Kepler)
- Apache Camel
Policy Framework
Access Security
Identity Services
Other Clients
Online Laboratory Notebooks
- Virtual Research Environments