Date 13 Jul 2021
Call-in Information Time: 11:00 am, Eastern Time (New York, GMT-04:00)
To join the online meeting:
Slack Attendees Indicating note-taker
Brian Lowe Benjamin Kampe Georgy Litvinov Michel Héon William Welling Benjamin Gross Ralph O'Flinn Don Elsborg Huda Khan Dang Vu Nguyen Hai Christoph Gopfert Agenda Dependencies between unit testshttps://vivo-project.slack.com/archives/C8RL9L98A/p1626082946083900 https://vivo-project.slack.com/archives/C8RL9L98A/p162608352608510 VIVO-PROXYStarting a collaboration with the University of Lausanne for the development of VIVO-PROXY Forking VIVO-PROXY Repo from UQAM to https://github.com/vivo-community/VIVO-PROXY Defining shapes or subgraphs for use in APIs, edit forms, indexes etc.Diagrams:existing architecture: https://docs.google.com/presentation/d/1raO98mklGUQgAc6wMMbgDEsHVk1zoCA3bq4Fyy21GjI/edit?usp=sharing Results of initial experiments with SHACL Defining more transparent N3-based templates? Mapping to simplified JSON objects for data ingestInspiration? William Welling: Apache Marmotta LDPath syntax https://marmotta.apache.org/ldpath/language.html SPARQL for list views/ indexing / URI finding Moving Scholars closer to the coreBuild messaging system first? versus Original option of typing into existing document modifiers:"win/win" opportunity: Scholars and VIVO both eliminate some complexity converting Scholars SPARQL queries to VIVO DocumentModifiers replacing URIFinders with fast, reliable Solr lookups Prioritizing future development items:quick wins / items for a more rapid release collaborative items for future sprints (Add/edit at will) spreadsheet: https://docs.google.com/spreadsheets/d/103P9P4v6yUBSb5BnVaK40NoGx1fIYyL8uaHKUubZWbE/edit?usp=sharing References 2019-01 Architectural Fly-in Summary#201901ArchitecturalFlyinSummary-Ingest VIVO in a Box current document for feedback: Future topics Prioritizing and planning post-1.12 development Forward-looking topics:frameworks: Spring / Spring Boot / alternatives Horizontal scalability Deployment Configuration : files / environment variables / GUI settings Editing / form handling Adding custom theming without customizing build Post-release prioritiesIngest / Kafka Advanced Role Management Moving Scholars closer to core - next steps Vitro JMS messaging approaches - reduxWhich architectural pattern should we take? What should the body of the messages be Incremental development initiativesIntegration test opportunities with the switch to TDB - requires startup/shutdown of external Solr ..via Maven Tickets Status of In-Review tickets
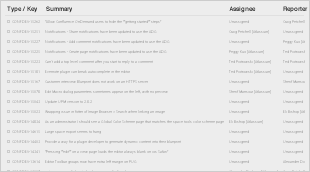
Notes Dependencies between unit tests VIVO-2003 - Vitro unit tests fail if not run in a certain order OPEN https://vivo-project.slack.com/archives/C8RL9L98A/p1626082946083900 https://vivo-project.slack.com/archives/C8RL9L98A/p162608352608510 Look into Spring Frameworks to help with the order of tests Look at dependency injection Maybe a static order for .1 then resolve for real in .2 VIVO-PROXY Starting a collaboration with the University of Lausanne for the development of VIVO-PROXY Forking VIVO-PROXY Repo from UQAM to https://github.com/vivo-community/VIVO-PROXY Defining shapes or subgraphs for use in APIs, edit forms, indexes etc. Diagrams: existing architecture: https://docs.google.com/presentation/d/1raO98mklGUQgAc6wMMbgDEsHVk1zoCA3bq4Fyy21GjI/edit?usp=sharing Results of initial experiments with SHACL Defining more transparent N3-based templates? Mapping to simplified JSON objects for data ingest Inspiration? William Welling: Apache Marmotta LDPath syntax https://marmotta.apache.org/ldpath/language.html SPARQL for list views/ indexing / URI finding Moving Scholars closer to the core Build messaging system first? versus Original option of typing into existing document modifiers: "win/win" opportunity: Scholars and VIVO both eliminate some complexity converting Scholars SPARQL queries to VIVO DocumentModifiers replacing URIFinders with fast, reliable Solr lookups Prioritizing future development items: quick wins / items for a more rapid release collaborative items for future sprints (Add/edit at will) spreadsheet: https://docs.google.com/spreadsheets/d/103P9P4v6yUBSb5BnVaK40NoGx1fIYyL8uaHKUubZWbE/edit?usp=sharing
Can we get a second slide with everything Brian said? (I suppose we could make the slide : ) ) Right now, the N3 patterns are defined in the JAVA generator classes, which are then processed in separate classes that do a lot of parsing of the submitted values, entering into the variables, and then assessing which N3 required strings are present, etc. A few years ago, we worked on a custom json simplification of this process It still used the processing pipelines underneath Is it also possible to include the Capability-map structure in the diagram? Don - I would also like to see this existing diagram built out a little bit more. Perhaps include some documentation on what we like or don't like for each component Draft notes on Google Drive