Time: 11:00 am, Eastern Time (New York, GMT-05:00)
To join the online meeting:
![]() Indicating note-taker
Indicating note-taker
Search index: approaches for configuration and processes
Mailing list messages
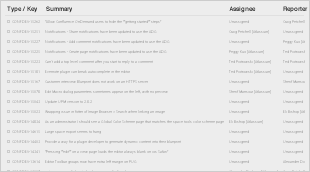
Status of In-Review tickets
|
Soft balls
Kitio Fofack ? Orcid and i18n
Received
|
Bugs (1.11)
|
Harry created a JIRA ticket to document what he had done with Docker. JIRA-1685.
Filipe from Sigma, new to VIVO on the call
Huda’s presentation
She was tasked with taking notes from the arch flyin. So this is her attempt at that. Requests people who attended fly in to add to notes.
People who want self contained vivo, others who want various components to work better and decouple components. So underlying question of how to decouple but make a better VIVO.
Left side is shapes, rdf, batch updates
Shapes - both for validating information and working with the indexing process.
The UI highlights things for end users but shapes translates that back to something concrete.
The bi-directional INDEX arrow really just means that the Indexing process is reading from the sparql api.
With UI Display, the auth/perms layer is there as a nod that this is what’s currently available with VIVO. Not vetted in with Product evolution yet.
Jim - way indexing is done now is that all info in index is public.
Richard - VIVO is still the interface to update info. Graphql only for view.
Mike - Any layered perms for graphql?
Richard - no plan for perms, this is for public display only.
Huda - so the auth/perm box between display and graphql/index is there as a placeholder, nobody is beholden to this.
Next - Combine slide - ETL - Huda is just going off of what people spoke of at fly in.
Seems like validation steps can be in several locations, after mapping, after disambiguation
Mike - elaborate on shapes.
Jim - shapes might not be a hard constraint on ingest, because we don’t just want to say all publications MUST have an author. But shapes can be used to validate the data to see if it’s optimal.
Huda - would be great to know what is actually in the store.
Don - would shapes be used in Validate - eg show all orphan pubs
Jim - thinks it would be used at ingest to prevent bad data from coming in.
Mike - Can use this to check if IRI’s are bad. Perhaps like a mini-graph for ETL
Next slide - of combine
Changes sets
Mike - distinguishing between first class objects ( people,pubs, grants ) vs others like relationships
Huda - perhaps a separate set that contains relationships.
Don - note that the data loads are done asynchronously. So we might not be able to validate the graph as it’s being loaded.
Richard - We determine our URIs for each object in a way that they are known to other objects. So the relationship URI can be know when loading another object.
Next slide - reasoning process
When to trigger reasoning - based on some event?
What is happening now is that when triple is added or removed, reasoning processes are triggered. Pro - things are kept in sync. Con - could be expensive at the wrong time.
Eg - add a faculty member, with class hierarchy we infer they’re people, mammals, etc
So danger of the nested russian doll system.
Mike - how many reasoners
Don - abox and tbox, both are used - Jim agreed
Mike - so we need more of this. So paris is a city, paris is in EU, we should query all cities in EU. We need to think much more about this.
Jim - VIVO had to strike a balance between performance and functionality with this.
Mike - So we should be able to get this information on demand, and not have to store the info per-se.
JIm - this wasn’t discussed at fly in. We should be able to configure the triple store and customize it.
Huda -Indexing process
Want to extract info from triple store - then create documents from that data.
Can shapes be used here. If a property changes does whole index need to be updated or perhaps just a portion of it. To some extent VIVO is doing this now. So moving forward based on a shape we can create new docs based on changes
Huda - indexing process slide 2
Everything is in place now.
Event configuration of when it happens. On request or when triples are added.
What goes into the index. Mapping.
Here are properties, here are queries, how do I map it to a target document.
What that mapping is it should be configurable. Using documentModifiers we can do this mapping.
Using abstract index we can implement different indexes like SOLR/Elastic/etc
Jim - we talked about modifying indexer to modify multiple indexes - eg one for traditional VIVO index and one used for GraphQL. When talking with Huda and Brian Lowe, maybe this isn’t the role. So do we want to shoehorn this into the existing configuration? Perhaps some data desired for an index might come from another source - eg RDBMS
Huda - shapes could inform indexing process.
Slide - Externalization
We have the triplestore and we have multiple ways of asking and receiving things from it. All of this goes through some abstraction - like sparqlAPI.