...
Few configuration options exist for the Paged content module out-of-the-box. Most of the configuration is associated with the relevant, dependent solution pack (Book or Newspaper). The configuration page at Administration > Islandora > Solution pack configuration > Paged Content Module (admin/islandora/solution_pack_config/paged_content) has the following options:
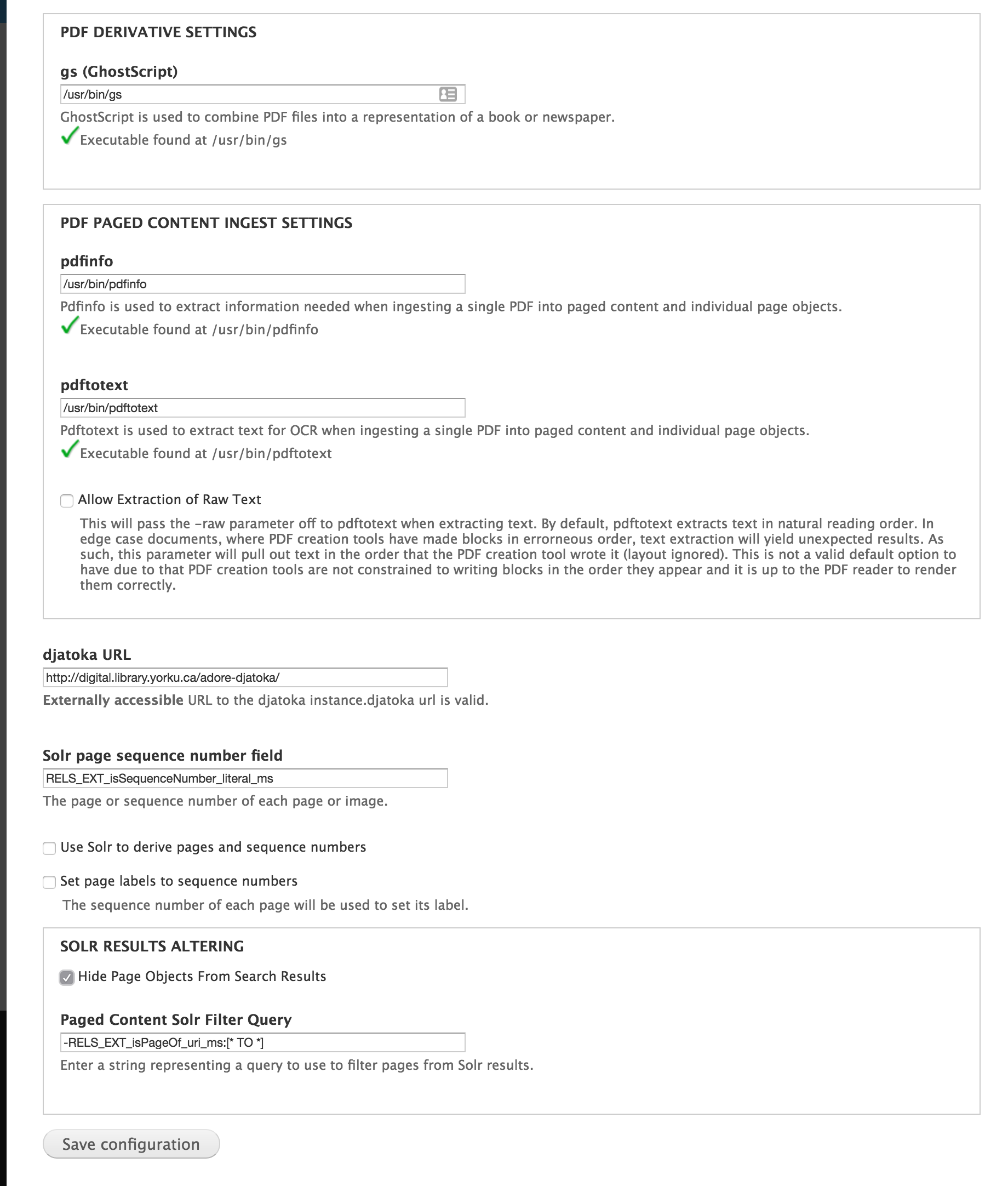 Image Added
Image Added
PDF Derivative Settings
Enter the path to the Ghostscript executable here. This will allow multi-page PDFs to be compiled using each page in the book or newspaper. More information about installing Ghostscript on your server can be found at the official project website, http://www.ghostscript.com/.
There is also an option to set the page label to the page's sequence number. On ingest, each page's label will be set to its sequence number. When reordering pages, all of the page labels will be updated with the new sequence numbers.
SOLR Results
The Paged Content Module also allows you to filter individual page objects from your search results. If you use this option, you will want to make sure you enable the "Aggregate OCR?" option when ingesting your book. That appends a consolidated OCR datastream to the book object, which allows it to be searched and returned.
 Image Removed
Image Removed
Content Models, Prescribed Datastreams and Forms
...
A page image ingested into a Paged Content collection using ImageMagick, the Large Image Solution Pack and the Islandora OCR modules, will have the following datastreams:
| OBJ | Original TIFF or JP2 file uploaded |
DC | Dublin Core record |
PDF | PDF derivative created by Ghostscript |
JP2 | JPEG 2000 derivative created by ImageMagick or Kakadu |
| JPG | Smaller JPEG derivative created by ImageMagick |
| TN | Thumbnail icon created from the image during the ingest process |
| RELS-INT | Internal Fedora relationship metadata defining the dimensions of the JP2 datastream |
| OCR | The raw output from Tesseract |
| HOCR | A converted version of the OCR datastream, intended to be more human-readable |
| RELS-EXT | Default Fedora relationship metadata |
...
