Page History
| Section | ||||
|---|---|---|---|---|
|

| Section | |||
|---|---|---|---|
|
Author: The Fedora Development Team
...
A good discussion of the Fedora digital object model (for Fedora 2 and prior versions) exists in a recent paper (draft) published in the International Journal of Digital Libraries. While some details of this paper have been made obsolete (e.g. Disseminators) by the Content Model Architecture, a refinement of the original Fedora concepts introduced in Version 3.0, the core principles of the model remain the same. The Fedora digital object model is defined in XML schema language (see The Fedora Object XML - FOXML). For more information, also see the Introduction to FOXML in the Fedora System Documentation. A data object in a Fedora repository describes content (data and metadata) and a set of associated behaviors or services that can be applied to that content. Data objects comprise the bulk of a repository.
Figure 1 below shows the basic data model of a Fedora digital object.

Figure 1: Fedora Digital Object Data Model
...
Datastreams represent the digital content that is the essence of the digital object (e.g., digital images, encoded texts, audio recordings). All forms of metadata, except system metadata, are also treated as content, and are therefore represented as Datastreams in a digital object. All Datastreams have the potential to be disseminated from a digital object. A Datastream can reference any type of content, and that content can be stored either locally or remotely to the repository system.
Datastreams
A Datastream is the element of a Fedora digital object that represents a content item. A Fedora digital object can have one or more Datastreams. Each Datastream records useful attributes about the content it represents such as the MIME-type (for Web compatibility) and, optionally, the URI identifying the content's format (from a format registry). The content represented by a Datastream is treated as an opaque bit stream; it is up to the user to determine how to interpret the content (i.e. data or metadata). The content can either be stored internally in the Fedora repository, or stored remotely (in which case Fedora holds a pointer to the content in the form of a URL). The Fedora digital object model also supports versioning of Datastream content (see the Fedora Versioning Guide for more information).
...
Decisions about what to include in a Fedora digital object and how to configure its Datastreams are choices as you develop content for your repository. The examples in this tutorial demonstrate some common models that you may find useful as you develop your application. Different patterns of Datastream designed around particular "genre" of digital object (e.g., article, book, dataset, museum image, learning object) are known as "content models" in Fedora.


Figure 2: Fedora Digital Object Datastreams
...
- Datastream Identifier: an identifier for the Datastream that is unique within the digital object (but not necessarily globally unique)
- State: the Datastream state of Active, Inactive, or Deleted
- Created Date: the date/time that the Datastream was created (assigned by the repository service)
- Modified Date: the date/time that the Datastream was modified (assigned by the repository service)
- Versionable: an indicator (true/false) as to whether the repository service should version the Datastream. By default the repository versions all Datastreams.
- Label: a descriptive label for the Datastream
- MIME Type: the MIME type of the Datastream (required)
- Format Identifier: an optional format identifier for the Datastream. Examples of emerging schemes are PRONOM and the Global Digital Format Registry (GDRF).
- Alternate Identifiers: one or more alternate identifiers for the Datastream. Such identifiers could be local identifiers or global identifiers such as Handles or DOI.
- Checksum: an integrity stamp for the Datastream which can be calculate using one of many standard algorithms (MD5, SHA-1, etc.)
- Bytestream Content: the "stuff" of the Datastream is about (such as a document, digital image, video, metadata record)
- Control Group: pertaining the the bytestream content, a new Datastream can be defined as one of four types, or control groups, as follows:
- Internal XML Metadata - In this case, the Datastream will be stored as XML that is actually stored inline within the digital object XML file. The user may enter text directly into the editing window or data may imported from a file by clicking Import and selecting or browsing to the location of the XML metadata file.
- Managed Content - In this case, the Datastream content will be stored in the Fedora repository and the digital object XML file will store an internal identifier to that Datastream. To get content, click Import and select or browse to the file location of the import file. Once import is complete, you will see the imported file in a preview box on the screen.
- External Referenced Content - In this case, the Datastream content will be stored outside of the Fedora repository, and the digital object will store a URL to that Datastream. The Datastream is "by reference" since it is not actually stored inside the Fedora repository. While the Datastream content is stored outside of the Fedora repository, at runtime, when an access request for this type of Datastream is made, the Fedora repository will use this URL to get the content from its remote location, and the Fedora repository will mediate access to the content. This means that behind the scenes, Fedora will grab the content and stream in out the the client requesting the content as if it were served up directly by Fedora. This is a good way to create digital objects that point to distributed content, but still have the repository in charge of serving it up. To create this type of Datastream, specify the URL for the Datastream content in the Location URL text box.
- Redirect Referenced Content - In this case, the Datastream content is also stored outside the repository and the digital object points to its URL ("by-reference"). However, unlike the External Referenced Content scenario, the Redirect scenario signals the repository to redirect to the URL when access requests are made for this Datastream. This means that the Datastream will not be streamed through the Fedora repository when it is served up. This is beneficial when you want a digital object to have a Datastream that is stored and served up by some external service, and you want the repository to get out of the way when it comes time to serve the content up. A good example is when you want a Datastream to be content that is stored and served by a streaming media server. In such a case, you would want to pass control to the media server to actually stream the content to a client (e.g., video streaming), rather than have Fedora in the middle re-streaming the content out. To create a Redirect Datastream, specify the URL for the content in the Location text box.
Digital Object Model
...
–-- An Access Perspective
Below is an alternative view of a Fedora digital object that shows the object from an access perspective. The digital object contains Datastreams and a set of object properties (simplified for depiction) as described above. A set of access points are defined for the object using the methods described below. Each access point is capable of disseminating a "representation" of the digital object. A representation may be considered a defined expression of part or all of the essential characteristics of the content. In many cases, direct dissemination of a bit stream is the only required access method; in most repository products this is only supported access method. However, Fedora also supports disseminating virtual representations based on the choices of content modelers and presenters using a full range of information and processing resources. The diagram shows all the access points defined for our example object.
For the access perspective, it would be best if the internal structure of digital object is ignored and treated as being encapsulated by its access points. Each access point is identified by a URI that conforms to the Fedora "info" URI scheme. These URIs can be easily converted to the URL syntax for the Fedora REST-based access service (API-A-LITE). It should be noted that Fedora provides a several protocol-based APIs to access digital objects. These protocols can be used both to access the representation and to obtain associated metadata at the same access point.

Figure 3: Fedora Digital Object Access Perspective
...
Fedora digital objects can be related to other Fedora objects in many ways. For example there may be a Fedora object that represents a collection and other objects that are members of that collection. Also, it may be the case that one object is considered a part of another object, a derivation of another object, a description of another object, or even equivalent to another object. For example, consider a network of digital objects pertaining to Thomas Jefferson, in which scholarly works are stored as digital objects, which are related to other digital objects representing primary source materials in libraries or museums. The composite scholarly objects can be considered a graph of related digital objects. Other types of objects can also be related to the scholarly object over time, for instance annotations about the scholarly object can be created by others and related to the original object. Also, digital objects can be created to act as "surrogates" or "proxies" for dynamically produced web content such as an Amazon page for a book relevant to the scholarly object. Such a network of digital objects can be created using Fedora, which in the abstract, would look like Figure 4.
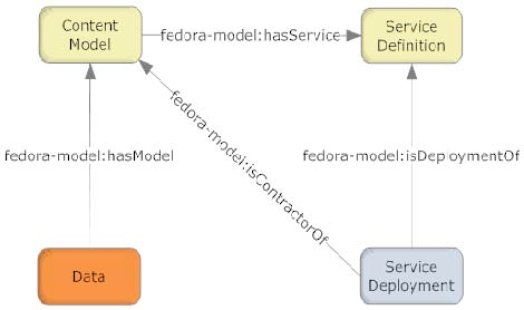
Figure 4: A Network of Digital Objects
Digital object relationship metadata is a way of asserting these various kinds of relationships for Fedora objects. A default set of common relationships is defined in the Fedora relationship ontology (actually, a simple RDF schema) which defines a set of common generic relationships useful in creating digital object networks. These relationships can be refined or extended. Also, communities can define their own ontologies to encode relationships among Fedora digital objects. Relationships are asserted from the perspective of one object to another object as in the following general pattern:
...
<MyCatVideo> <is a member of the collection> <GreatCatVideos>
Why are Fedora Digital Object Relationships Important?
The creation of Fedora digital object relationship metadata is the basis for enabling advanced access and management functionality driven from metadata that is managed within the repository. Examples of the uses of relationship metadata include:
- Organize objects into collections to support management, OAI harvesting, and user search/browse
- Define bibliographic relationships among objects such as those defined in Functional Requirements for Bibliographic Records
- Define semantic relationships among resources to record how objects relate to some external taxonomy or set of standards
- Model a network overlay where resources are linked together based on contextual information (for example citation links or collaborative annotations)
- Encode natural hierarchies of objects
- Make cross-collection linkages among objects (for example show that a particular document in one collection can also be considered part another collection)
Where is Digital Object Relationship Metadata Stored?
Object-to-Object relationships are stored as metadata in digital objects within a special Datastream. This Datastream is known by the reserved Datastream identifier of "RELS-EXT" (which stands for "Relationships-External"). Each digital object can have one RELS-EXT Datastream which is used exclusively for asserting digital object relationships.
A RELS-EXT Datastream can be provided as part of a Fedora ingest file. Alternatively, it can be added to an existing digital object via component operations of the Fedora management service interface (i.e., addDatastream). Refer to the FOXML reference example to see an example of the RELS-EXT Datastream in context. Modifications to the RELS-EXT Datastream are made via the Fedora management interface (i.e., modifyDatastream). The RELS-EXT Datastream is encoded as an Inline XML Datastream, meaning that the relationships metadata is expressed directly as XML within the digital object XML file (as opposed the relationship metadata existing in a separate XML file that the digital object points to by reference).
How is Digital Object Relationship Metadata Encoded?
Fedora object-to-object metadata is encoded in XML using the Resource Description Framework (RDF). The relationship metadata must follow a prescribed RDF/XML authoring style where the subject is encoded using <rdf:Description>, the relationship is a property of the subject, and the target object is bound to the relationship property using the rdf:resource attribute. The subject and target of a relationship assertion must be URIs that identify Fedora digital objects. These URIs are based on Fedora object PIDs and conform to the syntax described for the fedora "info" URI scheme. The syntax for asserting relationships in RDF is as follows:
...
- The subject must be encoded as an <rdf:Description> element, with an "rdf:about" attribute containing the URI of the digital object in which the RELS-EXT Datastream resides. Thus, relationships are asserted about this object only. Relationship directionality is from this object to other objects.
- The relationship assertions must be RDF properties associated with the <rdf:Description>. Relationship assertions can be properties defined in the default Fedora relationship ontology, or properties from other namespaces.
- Prior to 2.1, the objects of relationships were restricted to other Fedora digital object URIs. This has since been relaxed so that a relationship property may reference any URI or literal, with the following exception: a relationship may not be self-referential, rdf:resource attribute must not point to the URI of the digital object that is the subject of the relationship.
- There must be only one <rdf:Description> in the RELS-EXT Datastream. One description can have as many relationship property assertions as necessary.
- There must be no nesting of assertions. Specifically, there cannot be an <rdf:Description> within an <rdf:Description>. In terms of XML "depth," the RDF root is considered at the depth of zero. The must be one <rdf:Description> element that must exist at the depth of one. The relationship assertions are RDF properties of the <rdf:Description> that exist at a depth of two.
- Assertions of properties from certain namespaces for forbidden in RELS-EXT. There must NOT be any assertion of properties from the Dublin Core namespace or from the FOXML namespace. This is because these assertions exist elsewhere in Fedora objects and may conflict if asserted in two places. The RELS-EXT Datastream is intended to be dedicated to solely object-to-object relationships and not used to make general descriptive assertions about objects.
Resource Index - RDF-based Indexing for Digital Objects
Yes! The Fedora repository service automatically indexes the RELS-EXT Datastreams for all objects as part of the RDF-based Resource Index.
This provides a unified "graph" of all the objects in the repository and their relationships to each other. The Resource Index graph can be queried using RDQL or ITQL which are SQL-like query languages for RDF. The Fedora repository service exposes a web service interface to search the Resource Index. Please refer to the Resource Index documentation for details.
Section
...
5: The Content Model Architecture
Introduction
A major goal of the Fedora architecture has been to provide a simple, flexible and evolvable approach to deliver the "essential characteristics" for enduring digital content. Whenever we work with digital content, it is with an established set of expectations for how an intellectual work may be expressed. With experience we develop "patterns of expression" that are the best compromise we can craft between the capabilities of our digital tools and the intellectual works we create in digital form. We store our digital content with the expectation that all the important characteristics of our intellectual works will be intact each and every time we return to access them, whether it has been a few minutes or many years.
...
By combining these very different views, CMA has the potential to provide a way to build an interoperable repository for integrated information access in our organizations and to provide durable access to our intellectual works. As we introduce CMA concepts, we will discuss the rationale behind the design decisions. This is only the first generation of the CMA and, like the rest of Fedora, we expect it to evolve. An understanding of design decisions behind this "first-generation" CMA is a key element for community participation in future generations of CMA development. Most important is an understanding of three significant and interrelated developments in software engineering: (1) object-oriented programming, (2) design patterns, and (3) model-driven architectures. It is beyond the scope of this document to discuss any of these developments in detail but we will make reference in this document to aspects of them which inform the design of the CMA.
Content Model Architecture Overview
The Content Model Architecture (CMA) describes an integrated structure for persisting and delivering the essential characteristics of digital objects in Fedora. In this section we will describe the key elements of the architecture, how they relate, and the manner in which they function. The original motivation for the CMA was to provide a looser binding for Disseminators, an element of the Fedora architecture used to stream a representation to a client. However, the CMA as described in this document has encompassed a far greater role in the Fedora architecture, in many ways forming the over-arching conceptual framework for future development of the Fedora Repository.
...
While the CMA does not force you to use a specific content modeling language, Fedora 3.0 contains a reference implementation that enables the Fedora Repository to operate much as it did in prior versions. The following sections describe CMA in more detail and provide instructions on how to use the reference content modeling language so you can create your own CMA compatible objects immediately. Over time Fedora Commons will support the development of one or more content modeling languages as part of solution bundles that may be used by the community with minimum effort.
Specializing Digital Objects
One of the basic elements of the Fedora architecture is the Fedora digital object. Every digital object stored in a Fedora repository is some variation of the same basic Fedora digital object model. In Fedora, digital objects containing data (Data object) utilize an XML element called the Datastream to describe the raw content (a bitstream or external content). In Fedora 2 and prior versions, digital objects containing data may also have contained Disseminators. The Disseminator is a metadata construct used by Fedora to describe how a client can access content within the digital object or remotely referenced by the digital object. If you only needed to access the raw content, default functionality was provided by the Fedora Repository which did not require that a Disseminator be explicitly added to the digital object. Unfortunately, the older design meant that the Disseminator was repeated in every Data object.
...
Figure 5 illustrates the required relationships between fundamental object types in the CMA. In the CMA object serialization these relations are asserted as RDF statements in the digital objects' RELS-EXT Datastream. These relations are asserted only in the object at the origin of each arrow though typically these relations will be harvested and indexed within utilities such as Semantic Triplestores or relational databases to enable fast query over them, or into caches which permit rapid access to their functionality.
The "hasModel" relation identifies the class of the Data object. There may or may not be a Fedora digital object that corresponds to the identifier. If the identifier refers to an object it must be a CModel object and contain the base content model document. It is expected that many Data objects conform to a single Content Model (and have a relation asserted to the same CModel object). The Content Model characterizes the Data objects that conform to it.
The SDef object describes a Service and the Operations it performs. Defining a Service is the means by which content developers provide customized functionality for their Data objects. A Service consists of one or more Operations, each of which is an endpoint that may be called to execute the Operation. This approach is similar to techniques found in both object-oriented programming and in Web services. The CModel object uses the "hasService" relation to assert that its' class members provides a Service (and its associated Operations). A CModel is free to assert relations to more than one Service. A Service may be related to many CModels.
Deployment of a Service in a repository is accomplished by using the "isDeploymentOf" relation to the SDef object. The Service Deployment (SDep) object is local to a Fedora repository and represents how a Service is implemented by the repository. Finally, the SDep object asserts the "isContractorOf" to indicate the CModel (effectively the class of Data objects) for which it deploys Services. This permits the SDep to access the Datastreams in the Data object and user parameters when an Operation is called for a Data object.
Section
...
6: Fedora Repository Server
Thus far, we have talked about the component parts of a Fedora repository, but the larger picture is also important. A repository is made up of digital objects, but in what context do those objects exist and how is it that users interact with them?
Fedora Server Architecture
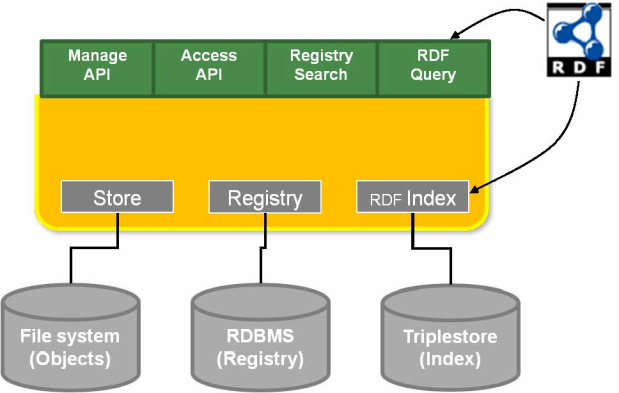
Figure 6: Fedora System Architecture (simplified)
This diagram shows in very general terms the structure of the entire repository. Users interact with the content of the repository by means of client applications, web browsers, batch programs, or server applications. These applications access the repository's data by
means of the four APIs by which Fedora is exposed: management, access, search, which are exposed via HTTP or SOAP, and the OAI provider API, which is exposed via HTTP.
Client and Web Service Interactions
This diagram gives another view of the larger context of a Fedora repository. Users perform common tasks such as ingesting objects, searching the repository, or accessing objects via client applications or a web browser. These client applications mediate this interaction with the repository via web services on the frontend, and on the backend, the repository interacts with web services to perform any data transformations that are requested by users. The transformed data is then passed back to the user via the frontend web services.
It is important to note that users only interact with the repository via the APIs, even though it may sometimes seem that they are interacting directly with an object, they are not.
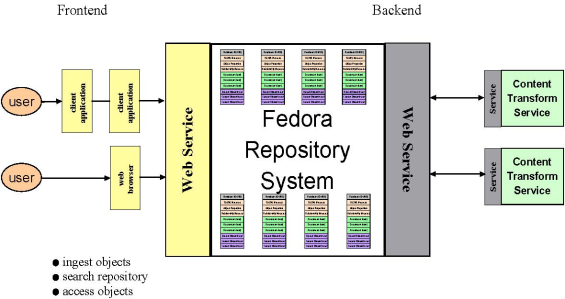
Figure 7: Client and Web Services Interaction
Overview
Content Tools