Page History
...
Note: Non-interactive steps will not appear in the Progress Bar! Therefore, your submitters will not even know they are there. However, because they are not visible to your users, you should make sure that your non-interactive step does not take a large amount of time to finish its processing and return control to the next step (otherwise there will be a visible time delay in the user interface).
Configuring SubmissionLookup service
SubmissionLookup service is a submission step in which the user is given the ability to search or load metadata from an external service (arxiv online, bibtex file, etc.) and prefill the submission form. It is underpinned by the Biblio Transformation Engine ( https://github.com/EKT/Biblio-Transformation-Engine ) framework.
About the Biblio-Transformation-Engine
The BTE is a Java framework developed by the Hellenic National Documentation Centre (EKT, www.ekt.gr ) and consists of programmatic APIs for filtering and modifying records that are retrieved from various types of data sources (eg. databases, files, legacy data sources) as well as for outputing them in appropriate standards formats (eg. database files, txt, xml, Excel). The framework includes independent abstract modules that are executed seperately, offering in many cases alternative choices to the user depending of the input data set, the transformation workflow that needs to be executed and the output format that needs to be generated.
The basic idea behind the BTE is a standard workflow that consists of three steps, a data loading step, a processing step (record filtering and modification) and an output generation. A data loader provides the system with a set of Records, the processing step is responsible for filtering or modifying these records and the output generator outputs them in the appropriate format.
The standard BTE version offers several predefined Data Loaders as well as Output Generators for basic bibliographic formats. However, Spring Dependency Injection can be utilized to load custom data loaders, filters, modifiers and output generators.
SubmissionLookup service in action!
When SubmissionLookup service is enabled, the user comes up with the following screen when a new submission is initiated:

There are three accordion tabs:
1) Search for identifier: In this tab, the user can search for an identifier in the supported online services (currently, arXiv, PubMed and CrossRef are supported). The publication results are presented in the tab "Results" in which the user can select the publication to proceed with. This means that a new submission form will be initiated with the form fields prefilled with metadata from the selected publication.
Currently, there are three identifiers that are supported (DOI, PubMed ID and arXiv ID). But these can be extended - refer to the following paragraph regarding the SubmissionLookup service configuration file.
User can fill in any of the three identifiers. DOI is preferable. Keep in mind that the service can integrate results for the same publication from the three different providers so filling any of the three identifiers will pretty much do the work. If identifiers for different publications are provided, the service will return a list of publications which will be shown to user to select. The selected publication will make it to the submission form in which some fields will be pre-filled with the publication metadata. The mapping from the input metadata (from arXiv or Pubmed or CrossRef) to the DSpace metadata schema (and thus, the submission form) is configured in the Spring XML file that is discussed later on.
Through the same file, a user can also extend the providers that the SubmissionLookup service can search publication from.
2) Upload a file: In this tab, the user can upload a file, select the type (bibtex. scv, etc.), see the publications in the "Results" tab and then either select one to proceed with the submission or make all of them "Workspace Items" that can be found in the "Unfinished Submissions" section in the "My DSpace" page.
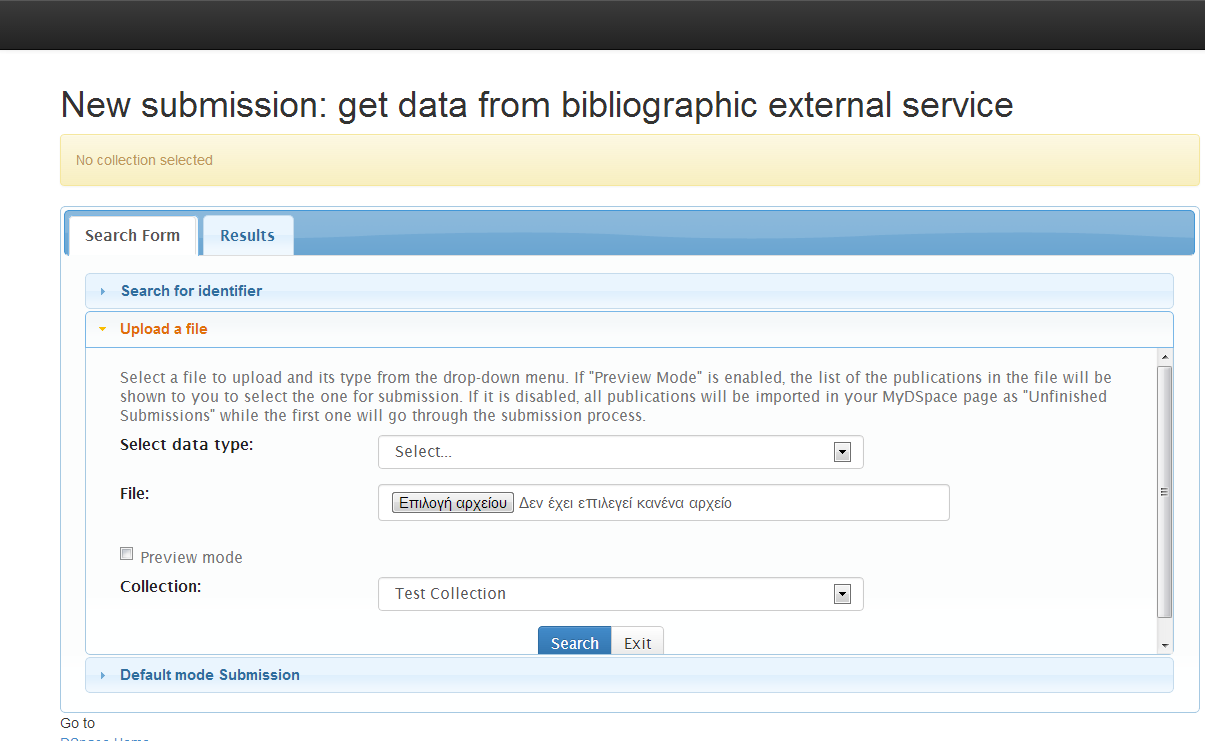
The "preview mode" in the figure above has the following functionality:
"ON": The list of the publications in the uploaded file will be show to the user to select the one for the submission. The selected publication's metadata will pre-fill the submission form's fields according to configuration in the Spring XML configuration file.
"OFF": All the publications of the uploaded file will be imported in the user's MyDSpace page as "Unfinished Submissions" while the first one will go thought the submission process.
3) Default mode submission: In this tab, the user can proceed to the default manual submission. The SubmissionLookup service will not run and the submission form will be empty for the user to start filling it.
SubmissionLookup service configuration file
The basic idea behind BTE is that the system holds the metadata in an internal format using a specific key for each metadata field. DataLoaders load the record using the aforementioned keys, while the output generator needs to map these keys to DSpace metadata fields.
The BTE configuration file is located in path: [dspace]/config/spring/api/bte.xml and it's a Spring XML configuration file that consists of Java beans. (If these terms are unknown to you, please refer to Spring Dependency Injection web site for more information.)
The service is broken down into two phases. In the first phase, the imported publications' metadata are converted to an intermediate format while in the second phase, the intermediate format is converted to DSpace metadata schema
Explanation of beans:
| Code Block | ||
|---|---|---|
| ||
<bean id="org.dspace.submit.lookup.SubmissionLookupService" /> |
This is the top level bean that describes the service of theSubmissionLookup. It accepts two properties:
a) phase1TransformationEngine: the phase 1 BTE transformation engine.
b) phase2TransformationEngine: the phase 2 BTE transformation engine
| Code Block | ||
|---|---|---|
| ||
<bean id="phase1TransformationEngine" /> |
The transformation engine for the first phase of the service (from external service to intermediate format)
It accepts three properties:
a) dataLoader: The data loader that will be used for the loading of the data
b) workflow: This property refers to the bean that describes the processing steps of the BTE. If no processing steps are listed there all records loaded by the data loader will pass to the output generator, unfiltered and unmodified.
c) outputGenerator: The output generator to be used.
Normally, you do not need to touch any of these three properties. You can edit the reference beans instead.
| Code Block | ||
|---|---|---|
| ||
<bean id="multipleDataLoader" /> |
This bean declares the data loader to be used to load publications from. It has one property "dataloadersMap", a map that declares key-value pairs, thas is a unique key and the corresponding data loader to be used. Here is the point where a new data loader can be added, in case the ones that are already supported do not meet your needs.
A new data loader class must be created based on the following:
a) Either extend the abstract class gr.ekt.bte.core.dataloader.FileDataLoader
in such a case, your data loader key will appear in the drop down menu of data types in the "Upload a file" accordion tab
b) Or, extend the abstract class org.dspace.submit.lookup.SubmissionLookupDataLoader
in such a case, your data loader key will appear as a provider in the "Search for identifier" accordion tab
| Code Block | ||
|---|---|---|
| ||
<bean id="bibTeXDataLoader" />
<bean id="csvDataLoader" />
<bean id="tsvDataLoader" />
<bean id="risDataLoader" />
<bean id="endnoteDataLoader" />
<bean id="pubmedFileDataLoader" />
<bean id="arXivFileDataLoader" />
<bean id="crossRefFileDataLoader" />
<bean id="pubmedOnlineDataLoader" />
<bean id="arXivOnlineDataLoader" />
<bean id="crossRefOnlineDataLoader" /> |
These beans are the actual data loaders that are used by the service. They are either "FileDataLoaders" or "SubmissionLookupDataLoaders" as mentioned previously.
The data loaders have the following properties:
a) fieldMap: it is a map that specifies the mapping between the keys that hold the metadata in the input format and the ones that we want to have internal in the BTE.
Some loaders have more properties:
CSV and TSV (which is actually a CSV loader if you look carefully the class value of the bean) loaders have some more properties:
a) skipLines: A number that specifies the first line of the file that loader will start reading data. For example, if you have a csv file that the first row contains the column names, and the second row is empty, the the value of this property must be 2 so as the loader starts reading from row 2 (starting from 0 row). The default value for this property is 0.
b) separator: A value to specify the separator between the values in the same row in order to make the columns. For example, in a TSV data loader this value is "\u0009" which is the "Tab" character. The default value is "," and that is why the CSV data loader doesn't need to specify this property.
c) quoteChar: This property specifies the quote character used in the CSV file. The default value is the double quote character (").
| Code Block | ||
|---|---|---|
| ||
<bean id="phase1LinearWorkflow" /> |
This bean specifies the processing steps to be applied to the records metadata before they proceed to the output generator of the transformation engine. Currenty, three steps are supported, but you can add yours as well.
-- More documentation is needed here --
| Info | ||
|---|---|---|
| ||
The configuration file hosts options for two services. BatchImport service and SubmissionLookup service. Thus, some beans that are not used in the first service, are not mentioned in this documentation. However, since both services are based on the BTE, some beans are used by both services. |
Overview
Content Tools