...
You are free to create ARK strings as you wish, provided you use only digits, letters (ASCII, no diacritics), and the following characters:
= ~ * + @ _ $ . /
The last two characters are reserved in the event you wish to disclose ARK relationships.
Another unique feature of ARKs is that hyphens ('-') may appear but are identity inert, meaning that strings that differ only by hyphens are considered identical; for example, these strings
ark:/12345/141e86dc-d396-4e59-bbc2-4c3bf5326152
ark:/12345/141e86dcd3964e59bbc24c3bf5326152
identify the same thing. The reason for this feature is that text formatting processes out in the world routinely introduce extra hyphens into identifiers, breaking links to any server that treats hyphens as significant.
...
ARKs distinguish between lower- and upper-case letters, which makes shorter identifiers possible (52 vs 26 letters per character position). The "ARK way", however, is to use lower-case only unless you need shorter ARKs. The restriction makes it easier for resolvers to support your ARKs in case they arrive from the world with mixed- or upper-case letters, which happens regrettably often due to the lingering 1960's-era view that identifiers are case-insensitive (one sign of which is the prominence of the Caps Lock key on most computer keyboards).
Alphanumeric characters (letters and digits) are generally adequate, but it is recommended to use the betanumeric subset, consisting only of digits and consonants minus 'l' (letter ell, often mistaken for the digit 1):
0123456789bcdfghjkmnpqrstvwxz
This happens to be the repertoire produced from minters (unique string generators) supported by the Noid tool and N2T.net (used by ezid.cdlib.org and the Internet Archive), which creates transcription-safe strings using the strongest mainstream identifier check digit algorithm. When generating unique strings automatically, the absence of vowels helps avoid accidentally creating words that users can misconstrue.
Regarding assignment, one common strategy is to leverage legacy identifiers. For example, a museum moth specimen number cd456f9_87 might be advertised under the ark:/12345/cd456f9_87. Some legacy identifiers may need to be altered in view of ARK character restrictions. The second common strategy is to make up entirely new strings for your ARKs. In this case it is important to consider whether to make them opaque or non-opaque (or a bit of both).
What are opaque identifiers?
Persistent identifier strings are typically opaque, deliberately revealing little about what they're assigned to, because non-opaque identifiers do not age or travel well. Organization names are notoriously transient, which is why NAANs are opaque numbers. As titles and dates are corrected, word meanings evolve (eg, innocent older acronyms may become offensive or infringing), strings meant to be persistent can become confusing or politically challenging. The generation and assignment of completely opaque strings comes with risk too, for example, numbers assigned sequentially reveal timing information and strings containing letters can unintentionally spell words (which is why vowels are missing from the recommended character repertoire).
...
ARKs are not required to be opaque, but it is recommended that the base object name be made opaque, since it tends to name the main focus of persistence. If any qualifier strings follow that name, it is less important that they be opaque. To help choose your approach to opacity, you may wish to consider compatibility with legacy identifiers and ease of string generation and transcription (eg, brevity, check digits). New strings can be created (minted) with date/time, UUID, and number generators, as well as Noid (Nice Opaque Identifiers) minters.
Opaque strings are "mute" and therefore challenging to manage, which is why ARKs were designed to be "talking" identifiers. This means that if there's 131533174, an ARK that comes in to your server with the '?' inflection should be able to talk about itself.
Anchor servingARKs servingARKs
How do I make server content addressable with ARKs?
| servingARKs | |
| servingARKs |
First, decide what the user experience of accessing your ARKs will be, for example, a spreadsheet file, a PDF, an image, a landing page filled with formatted metadata and a range of choices, etc. Whichever you choose, plan for your server to be able to respond with metadata if your ARK should arrive with a '?' inflection after it.
Otherwise, serving ARKs is like serving URLs. Normally incoming URL strings address (get mapped to) content that your web server returns. If your server is ARK-aware, incoming ARKs (expressed as URLs) must be mapped to the same content. A common approach is to map the ARK to the URL using a software table that you update whenever the URL changes. In this case your server is acting as a local resolver. If you don't want to implement this yourself, there are ARK software tools and services that can help.
Another approach is to run your web server without change, but instead of updating local tables, you would update ARK-to-URL mapping tables residing at a non-local resolver. Examples of this can be found among vendors and in any organization that updates tables via EZID.cdlib.org (which, due to a special relationship, updates resolver tables at n2t.net).
How do I cite or advertise an ARK?
The URL (https or http) form of the ARK is preferred, for example,
https://n2t.net/ark:/99166/w66d60p2
An ARK meant for external use is generally advertised (released, published, disseminated) in this way in order to be an actionable identifier. If a more compact visual display of an ARK is needed, it should be hyperlinked; for example, a compact display of an HTML hyperlink can be achieved with
<a href="https://n2t.net/ark:/99166/w66d60p2"> ark:/99166/w66d60p2 </a>
An important decision is whether your URL-based ARKs will use the hostname of your local resolver or the N2T.net resolver. If local control or branding is important enough, you would advertise ARKs based at your local resolver (see about serving content with ARKs). If you're concerned about the stability of your local hostname, you would advertise your ARKs based at n2t.net (see examples of both).
Resolving your ARKs through N2T is always possible for users, regardless of how you advertise them.
...
Yes, ARKs can be assigned at any level of granularity, such as to a manuscript, to chapters inside it, to chapter sections, subsections, etc. An ARK can also be assigned to a thing that encloses other things. In ARKs the character '/' is reserved to help the recipient understand about containment, for example, the first object below contains the second:
ark:/12148/btv1b8449691v
ark:/12148/btv1b8449691v/f29
That's the containment qualifier. There's only one other ARK qualifier, and it indicates variant forms of a thing by using the reserved character '.' in front of a suffix. For example, if these ARKs identify documents,
ark:/12148/btv1b8449691v/f29.pdf
ark:/12148/btv1b8449691v/f29.html
because they differ only by the suffix .pdf or .html, it can be inferred that they identify two different forms of the same document.
...
By obtaining a NAAN, an organization gets the exclusive right to create ARKs "under" that NAAN. Your NAAN is part of a prefix in front of all your ARKs. The set of ARKs you can create is infinite and is known as your NAAN's namespace, and your NAAN namespace is a sub-namespace (subset) of the ARK namespace (the set of all possible ARKs). For example, the Internet Archive's NAAN namespace is all ARKs starting with "ark:/13960/". NAANs effectively subdivide the ARK namespace into non-overlapping sub-namespaces, each one holding an infinite number of possible ARKs. Since organizations can only create ARKs in their own namespaces, it is impossible for ARK assignments between organizations to do not conflict.
NAANs play a key role in resolution. For example, if a resolver cannot find an incoming ARK in its database, it looks at the incoming NAAN and redirects the ARK to the local resolver registered with the NAAN. This is precisely what the N2T.net resolver does. Any local resolver could be configured to return the favor for any incoming ARKs with NAANs that it doesn't know about, simply by redirecting them to N2T.
...
Namespaces and sub-namespaces work on the principle that every time whenever a prefix defines a namespace, it only needs to be "extended" (adding characters to the end of the prefix) to create a new sub-namespace containing directly under it. The sub-namespace also contains an infinite number of possible ARKs. There is potentially a sub- namespace associated with every prefix.
...
Examples like those in the above table are quite common. The first is for all ARKs and the second is for all ARKs under ark:12345. The third is the shoulder concept, described below, which is the next subdivision under the NAAN; note that it has no "/" after it. The fourth, a complete ARK-as-prefix example, shows that an object ARK is itself is also a namespace, with potentially an infinite number of "sub-ARKs" that descend from it to name object parts and variants. The practice of creating new namespaces by adding information to an existing namespace is very widely used and pre-dates the Internet (eg, a neighbor, who lives at flat #3B, receives mail at 1234 Main Street, #3B, Springfield, IL, USA)common and very old, for example, in "snail mail" terms, you might be from Springfield or, more precisely, Flat #3B, 4321 Main Street, Springfield, Ontario, Canada.
Anchor shoulder shoulder
What is a shoulder?
| shoulder | |
| shoulder |
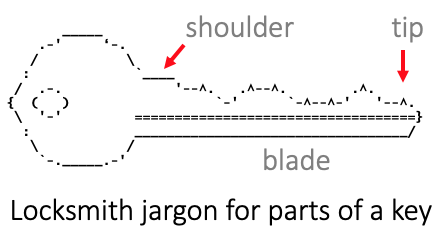
A shoulder is a sub-namespace under a NAAN namespace. It is the set all ARKs starting with a short, fixed extension to the NAAN. For example, in
...
the shoulder, can be designated by /x5 if the context is clear, but it is often best to use its fully qualified, globally unique designation of ark:/12345/x5. In the classic namespace tradition, the shoulder is the set of all possible ARKs starting with the longer shoulder name. Note that while the shorter shoulder name (the extension to the NAAN) is set off from the NAAN by a "/", it is not followed by any separator character that marks the end of the shoulder. Our use of the term is borrowed from the locksmith profession, which understands sets of keys to be defined by fixed (unvarying) "shoulders" that precede the varying shapes ("blades") that end at the tip of the keyfollow it.
What is the purpose of a shoulder?
Shoulders help organize ARKs in a NAAN namespace. Just because it contains an infinite number of possible ARKs to assign does not mean that finding an unassigned ARK is easy.
A shoulder is analogous to A shoulder is analogous to a guest room in your house. Imagine a colleague, SamSally, who took takes in a long-term lodger, Larry. SamSally's home is very spaciousextremely spacious (in fact it is infinite), but Sam Sally complains that Larry leaves things permanently lying about around all over the house: his coat on the kitchen chair, glasses on the dining table, book on SamSally's desk, slippers next to the sofa, coffee cup on the bathroom sink, etc. By special the terms of his lodging agreement, once placed, Larry's things, once placed, cannot be moved. Needing to find new places (ARKs, in the analogy) for things, Sam But Sally, who also needs room for things and might – one never knows – take on new lodgers, is stuck forever noticing and trying checking not to disturb Larry's stuff. You shake your head in sympathy and , but quietly decide plan that if should you ever took take in a long-term lodger (an independent assignment operation under your organization), the lodging agreement would set aside a guest room (a shoulder) with the requirement that the lodger's things could can only be placed in the that guest room. Under such an agreement, Larry's stuff would have left all of Sally's home undisturbed except for the one room set aside for Larry, and she could then easily take on any number of new lodgers under similar agreements.
So shoulders allow ARK assignment operations under a NAAN to be delegated to autonomous projects or divisions, just as NAANs do under the overall ARK namespace. Even if an organization initially only wants to use ARKs for one project, plans may change. If other needs for ARKs arise later, setting aside a new shoulder for each new project or division makes it easy to ensure that autonomous assignment streams – present, past, or future – won't conflict with each other, thanks to non-overlapping namespaces. (Shoulders can also ease the namespace splitting problem.)
...
the "/" after "/x5" implies
- that
ark:/12345/x5is also an object and - that the object named
ark:/12345/x5/wf6789/c2/s4.pdfis contained in it.
Both are likely untrue, at least in any way that can be easily explained to a user. It may seem natural to add a "/" because it makes the shoulder boundary obvious to in-house ARK administrators, but they are specialists who can be inconvenienced by the non-obvious. It . Recalling that in-house specialists can afford to be inconvenienced, it doesn't help the end user who either is either uninterested and confused by your internal operational boundaries, or is so very interested that they may try you risk their trying to hold you to account for their inferences (eg, about consistent support levels across objects sharing the apparent containing object). Less transparency about administrative structure hides messy details and can save you user-support time in the end.
In fact, in-house ARK administrators always know where the shoulder ends, provided it was chosen using the "first-digit convention". A primordinal shoulder is a sequence of one or more betanumeric letters ending in a digit. This means that the shoulder is all letters (often just one) after the NAAN up to and including the first digit encountered after the NAAN. Another advantage of primordinal shoulders is that there is an infinite number of them possible under any NAAN.
...
There are different ways to implement a shoulder. Fundamentally, a shoulder is a deliberate practice that is created from a decision you make to assign ARKs that start with a particular extension to your NAAN. A shoulder can then emerge from ARK assignment "emerge" as ARKs are assigned according to practices that have consciously reserved and use used that extension.
Having said that, there are a couple of cases where shoulder creation implementation can involve another a "creation" step. A system such as ezid.cdlib.org supports these the kinds of "user-based" shoulders above (that emerge from user practice, eg, Smithsonian), but it also supports the creation of system-recognized shoulders with accompanying minter services and registered API access points. To implement In contrast, implementing a user-based shoulder requires no separate explicit shoulder creation step, but does involve the creation of one or more ARKs under that start with that shoulder.
In another case, to implement a shoulder under one of a handful of shared NAANs (below), your organization must first register to to reserve a shoulder under a shared NAAN.
...
For people with enough training, it is easy to recognize and exploit ARKs with the immutable attributes or connotations of these NAANs. For example, if you are responsible for reviewing broken link reports for , 99999 and 12345 ARKs can safely be ignored. Despite providers' best efforts, test ARKs frequently "escape into the wild", so the fixed semantics of these NAANs can mitigate their potential to end up confusing users and link checkers. While both NAANs may have ARKs that do actually resolve, some for a long time, 99999 ARKs are meant for test use, often at scale, and 12345 ARKs are meant for small-scale use as examples in documentation.
To create ARKs that use these shared NAAN-based semantics without conflict, there needs to be a way to reserve namespaces (shoulders) under the NAANsNAAN in question, and that requires a public shoulder registry. To register a shoulder under a shared NAAN requires filling out the same online form used to request a NAAN.
...